명사구 수식언 유무 및 위치에 따른 비전형적 구문구조 산출률에서 청년층과 노년층 집단 간 차이
Age-Related Differences in Production of Non-Canonical Syntactic Structures as a Function of Modifiers to Noun Phrases
Article information

Abstract
배경 및 목적
본 연구는 청년층과 노년층을 대상으로 명사구 수식언 유무 및 위치에 따른 문장 산출 형태를 확인함으로써 문장의 길이 및 논항구조의 형태에 따라 문장 산출 형태가 달라지는 지 알아보고자 하였다.
방법
대상자는 정상 청년층 50명과 정상 노년층 50명이다. 본 연구의 과제는 흩어진 목표 문장을 의미를 생각하며 기억을 하고 10초 후 회상하여 산출하는 문장 산출 과제 및 문장 산출 과정에 필요한 인지 기능을 확인할 수 있는 작업기억 과제와 장기기억 과제이다. 정반응률과 비전형적 구문구조 산출률이 분석되었으며, 작업기억 과제와 장기기억 과제의 점수는 회귀분석에서 다른 인지 기능 변수와 함께 문장 산출 수행과의 관계를 알아보는 데 사용되었다.
결과
명사구 수식언 유무 및 위치에 따른 문장 유형에서 노년층의 정반응률이 청년층에 비해 유의하게 낮았다. 명사구 수식언의 목적어수식 문장에서의 노년층의 정반응률이 다른 문장 유형에서의 것보다 낮았다. 비전형적 구문구조 산출률은 노년층이 청년층에 비해 유의하게 높았고, 수식언의 목적어수식 문장에서의 노년층의 비전형적 구문구조 산출률이 다른 문장 유형에서의 것보다 높았다. 실험에 사용된 인지 기능 관련 변수 중 수식언의 목적어수식 조건에서의 비전형적 구문구조 산출률을 가장 잘 예측하는 변인은 작업기억 과제 총 점수와 지연 회상 과제의 점수였다.
논의 및 결론
노년층은 노화로 인한 인지 기능 감퇴로 문장 처리에 대한 부담을 느껴 청년층 보다 낮은 정반응률을 보였다. 또한 노년층은 청년층과 달리 비전형적 구문구조 산출률이 높았는데 이는 수식언으로 인해 길어진 문장에서 도치를 통해 인지적 부담감을 해소하려는 전략으로 해석해볼 수 있다.
Trans Abstract
Objectives
This current study investigated age-related differences in production of noncanonical syntactic structures when the function of modifiers to noun phrases (NPs) was systematically manipulated. We manipulated the modifiers by varying the length and location of modifiers in relation to the NPs.
Methods
A total of 100 individuals (young 50s, elderly 50s) participated in the study. We developed a sentence rearrangement task, in which the sentential segments were randomly presented in a computer screen and participants were asked to construct a sentence by rearranging the segments (Subject, Object, Verb). The syntactic structures which were presented to participants consisted of three conditions: 1) No modifier, 2) Modifiers with a Long-Subject, and 3) Modifiers with a Long-Object.
Results
The elderly group demonstrated significantly lower accuracy across all conditions compared to the younger group. Both groups presented lower performance under the condition of modifiers either with a long object or with a long subject compared to the condition without modifiers. Elderly adults demonstrated differentially greater difficulties in constructing sentences with modifiers with a long object than the other conditions. Results from the ratio of non-canonical syntactic structures revealed that the elderly group showed a higher ratio of non-canonical sentences under the long-object condition. The significant predictors for the ratio of non-canonical syntactic structures in the elderly group were the working memory and the delayed recall test score that accounted for approximately 30.4%.
Conclusion
The elderly group demonstrated greater difficulties in sentence construction tasks. When the cognitive load increased through manipulating of the location and length of modifiers to the NPs, elderly adults exhibited a higher ratio of producing non-canonical structures, indicating that they employed a strategy to engage the non-canonical structures to reduce the cognitive burden from the long-object modifiers.
화자와 청자가 의사소통을 하기 위해서 화자는 문장을 산출하고 청자는 그 문장을 듣고 이해하여 그에 적절한 문장 형태로 재 산출하게 된다. 노화가 진행됨에 따라 이러한 일련의 의사소통 과정의 처리 속도가 느려질 수 있으며, 언어 처리를 위해 필요한 부담감도 증가하게 된다. 한국 사회는 고령화사회에 진입하였고(Korea National Statistical Office, 2017), 이로 인해 사람들은 점차 노화에 대한 관심이 높아져가는 가운데 노년층의 건강 및 사회 · 경제적 문제에 대한 우려의 목소리도 늘어가고 있다. 노화가 진행되면 문장 산출 능력은 쇠퇴한다. 이는 문장 산출이 다양한 인지 기능이 요구되는 복잡한 과정이기 때문이다. 그러므로 고차원적인 인지 처리과정이 요구되는 문장 산출 과제를 통해 노화로 인한 문장 산출 능력 및 인지 기능의 변화를 알아보는 연구가 필요한 실정이다(Ferreira & Cokal, 2015).
문장을 산출하기 위해서 화자는 각 언어의 논항구조를 고려하여 문장 구성요소들을 배열하게 된다. 여기서 문장 성분들의 배열 순서를 어순(word order)이라 지칭한다. 언어에 따라 어순 배열은 조금씩 상이한데, 대개 주성분에 해당하는 주어(subject, 이하 S), 목적어(object, 이하 O), 동사(verb, 이하 V)의 배열로 그 순서를 결정한다. 대부분의 언어는 주성분으로 가능한 여섯 가지 배열 조합 중, 지배적인 세 가지 어순(SOV, SVO, VSO) 중 하나에 속한다. 한국어는 지배적인 세 가지 어순 중에서 ‘SOV’를 따르는 언어이다(Lee & Chae, 1999; 이익섭 & 채 완, 1999). 어순은 주성분의 배열이 고정되어 있는 언어(고정 어순, fixed word order)와 주성분의 배열이 자유로운 자유 어순(free word order) 언어로 나뉜다. 이중에 한국어는 조사의 사용으로 인해 비교적 자유 어순(free word order) 또는 부분 자유 어순(partial free word order)의 언어로 분류되기도한다(Lee, 2003; Heo, 2003; Lim, 2007).
자유 어순 언어는 고정 어순 언어에 비해 문장 성분의 이동이 비교적 자유롭다. 예를 들어 ‘목적어+주어+서술어’와 같이 ‘목적어’가 ‘주어’보다 선행해도 문법적으로 오류가 있다고 여기지 않는다. 그럼에도 어순에는 전형성(canonicity)이 존재한다. 어순이 자유로운 독일어 화자가 문장을 처리하는 과정을 기능적 자기공명영상(functional Magnetic Resonance Imaging, fMRI)으로 뇌의 기능을 촬영하였는데, 비전형 어순을 처리할 때 전두엽의 브로카 영역이 활성 되었으며, 과제 수행력도 전형 어순에 비해 현저히 떨어졌다(Bahlmann, Rodriguez‐Fornells, Rotte, & Münte, 2007). 한국어 역시 어순이 비교적 자유로운 언어이지만 한국어 화자가 선호하는 어순은 기본 어순인‘SOV’라는 것을 학자들 대부분이 인정하고 있는 바이다(Lim, 2007). 언어 습득 시기부터 ‘SOV’의 어순 형태를 주로 사용하며 이는 연령이 증가하면서 어순의 변화가 일어나긴 하지만(Cho, 1982), 대중적인 어순은 ‘SOV’형태인 것이다. 이는 21세기 세종기획 말뭉치 자료를 분석한 Nam (1988)의 연구에서 출현 빈도 비교로 분명하게 나타난다(SOV 어순 출현빈도 약 92%, OSV 어순 출현빈도 약 8%). Sung (2015)에서는 한국어 노년층 화자가 ‘SOV’ 어순을 선호한다는 결과를 보고하였다. 한국어 노년층 화자에게 세가지 문장 유형으로 구성된 문장 이해 과제를 전형적 구문 구조와 비전형적 구문구조로 각각 제시하여 문장 유형 및 어순 전 형성에 따른 수행 능력 차이를 알아보았다. 그 결과, 전형적인 구문 구조를 가진 어순에서의 수행 능력이 비전형적이 구문구조를 가진 어순에서 보다 좋았다. 또한 Oh와 Sung 그리고 Sim (2016)의 연구에서 문장 이해 과제를 통해 어순 전형성을 변수로 청년층과 노년층을 대상으로 ERP 실험을 한 결과, 전형적인 문장에 비해 비전형적 문장에서의 ERP 진폭이 유의하게 높게 나타나기도 했다. 즉, 피험자들은 전형적 어순의 문장에서 보다 비전형적 어순의 문장에서 더 큰 어려움을 느꼈으며, 특히 노년층이 청년층보다 비전형 어순에서 더 큰 인지적 부담을 느끼는 것으로 해석된다. 이렇게 어순에 따라 수행도 차이가 생기는 원인에 대하여 다양한 연구들은 비전형적인 어순의 문장 처리가 전형적인 어순의 문장 처리에 비해 인지적 처리 부담이 증가하기 때문인 것으로 보고하고 있다(Koizumi et al., 2014).
이처럼 많은 연구가 ‘SOV’ 구문구조를 한국어의 전형 어순으로 분류하고 있으며, ‘OSV’ 구문구조를 비전형 어순이라 지칭하는 것에 의의가 없는 것으로 보인다. 본 연구에서도 선행 연구들을 따라 ‘SOV’ 어순 구조를 전형적 구문구조로 ‘OSV’ 어순 구조를 비전형적 구문구조로 정의하고자 한다. 보통은 문장 산출 과정에서 전형적인 어순을 선호하지만 특정 상황에서는 비전형적 구문구조가 산출되기도 하는데, 이는 수식언으로 인해 주성분 간의 거리가 멀어진 논항구조 형태의 문장을 산출할 때이다. 수식언이란 문장을 구성하는 문장 성분 중 ‘부속성분’에 해당하며 문장에서 간접적인 기여를 하는 성분이다(Lee, 2005; Song, 2007; Kim, 2014). 수식언은 문장에서 체언이나 용언 앞에 놓여 그 뜻을 꾸미거나 한정하는 기능을 하는데, 관형사와 부사가 수식언에 해당한다. 관형사는 주로 체언을 수식하고 부사는 주로 용언을 수식한다(Heo, 1975). 즉, 관형사는 주어나 목적어 앞에 놓여 그 대상이 가지는 성질을 한정하거나 풍부하게 하고 부사는 서술어 앞에 놓여 서술어의 속성을 한정하거나 풍부하게 하는 것이다. 그런데, 이러한 수식언이 문장에 위치하면 문장의 길이가 다소 길어지고 처리를 하는데 더 많은 노력을 요구하게 되며, 수식언의 위치가 주어와 목적어 사이일 경우, 주어와 서술어 간의 거리를 벌려 놓음으로써 논항구조의 파악을 어렵게 한다.
문장의 길이가 길어지고 논항구조 파악이 어려워지게 되면 화자나 청자는 일종의 영역 최소화 전략을 사용하게 된다(Yamashita & Chang, 2001). Hawkins (2007)에 따르면 화자나 청자가 문장을 처리하는데 인지적인 부담을 느끼게 되면, 서술어 및 서술어와 관련된 논항들 간의 거리를 좁힘으로써 논항구조의 의미나 형태 파악을 수월하게 하려는 움직임을 보이게 되는데 이를 ‘영역 최소화 전략’이라고 한다. Yamashita와 Chang (2001)은 문장 산출 과제를 수행하는 상황에서 피험자들은 수식언이 목적어를 수식함으로써 문장의 주어와 서술어 간의 거리가 멀어지는 유형에 수식언을 포함한 목적어 구를 주어 앞으로 선치하여 서술어가 필수적으로 요구하는 논항들을 쉽게 파악하고자 했다. 또한 Nam과 Hong (2013)은 문장 산출 시 수식언이 직접 목적어를 꾸밈으로써 그 논항의 길이가 길어질 경우 간접 목적어 구를 직접 목적어 구 앞으로 위치시킴으로써 서술어와 필수적 논항들 사이의 거리를 응집시키는 전략을 사용하여 처리 부담을 감소시키고자 하였다. 이처럼 영역 최소화 전략은 서술어와 서술어가 필수적으로 요구하는 논항들을 파악하는데 소요되는 시간을 단축하고자 하는 경제성과 효율성을 고려한 전략임을 알 수 있다.
그런데 이러한 영역 최소화 전략에 관한 연구는 상대적으로 인지 기능이나 문장 산출 능력이 잘 보존된 청장년층을 대상으로 한 연구가 많으며, 노년층을 대상으로 한 연구는 부족하다. 영역 최소화 전략은 문장을 처리하는데 느끼는 인지적 부담을 줄이고 경제성과 효율성을 높이는 전략이다. 그러므로 상대적으로 인지 기능에 노화가 진행되고 있는 노년층을 대상으로 전략 사용 양상을 확인하여 이러한 전략이 문장을 처리하는데 효율적인 전략인지를 판단하는데 민감한 지표가 될 수 있을 것이다. 또한 이러한 영역 최소화 전략을 사용하는 것이 인지적 부담을 줄여 경제성과 효율성을 높이기 위한 전략이라는 설명은 있지만 이와 관련된 인지 기능과의 관계를 보다 심층적으로 설명하는 연구는 많지 않다. 노화로 인한 인지 기능 감퇴와 언어 처리 간 상관관계는 다양하게 보고되고 있다(Hultsch, Hertzog, & Dixon, 1990; Caplan, DeDe, Waters, Michaud, & Tripodis, 2011). 이러한 인지 기능 감퇴 중, 작업기억 손상 및 장기기억 손상에 따른 언어 능력 감퇴에 대한 보고가 다양하게 이루어지고 있지만, 이러한 기능과 문장 산출의 비전형적 구문구조 산출과의 연관성을 노화의 측면에서 살피는 연구는 드물다(Lee & Sung, 2015; Park, 2014).
이에 본 연구에서는 선행연구(Yamashita & Chang, 2001)에서 사용한 실시간 문장 산출 과제를 참고하여 인지 기능과 문장 산출 능력에서 차이가 있는 두 연령 집단을 비교하여 연령에 따라 문장 산출을 위한 전략적인 차이가 나타나는지 알아보고자 한다. 즉, 선행연구에서 기억력의 부담을 주는 상황에서 청년층에게 나타났던 주성분 간의 거리를 응집시키고자 하는 영역 최소화 전략이 인지·언어적으로 노화가 진행되고 있는 정상 노년층에게도 같은 형태로 나타날 지 알아보고자 하며, 나아가 인지 기능 중에서 이러한 경향을 예측해주는 주요 변수가 무엇인지 살펴보고자 한다. 본 연구에서는 인지 기능 중에서도 노화에 따른 인지 기능 저하를 예리하게 예측할 수 있다고 입증된 변수들을 ‘인지 기능 관련 변수’라 지칭하고 변수에 교육년수, 작업기억 능력과 장기기억 능력을 포함하고 인지 기능 저하를 판별하기 위한 검사인 한국판 간이 정신 상태 검사(Korean-Mini Mental State Examination [K-MMSE]; Kang, 2006) 점수를 포함하였다. Yamashita와 Chang (2001)에서 고안한 본 연구의 문장 산출 과제는 기존의 문장 따라말하기 과제와 다르게 주어진 정보를 저장하고 조작하고 일정 시간 후 산출하는 과정이 포함되어 있기 때문에 기존의 문장 따라말하기 과제와는 성격을 달리할 것이다. 그렇기 때문에 정보의 저장과 조작을 동시에 요구하는 능력인 작업기억 능력과 저장된 정보를 인출하는 과정을 포함하고 있는 장기기억 능력은 본 연구의 과제를 수행하는데 필요한 기술과 전략과 관계가 있을 것으로 예상된다.
본연구의연구질문은다음과같다.
첫째, 명사구 수식언 유무 및 위치에 따른 문장 산출에서 청년층과 노년층의 집단 간 정반응률 차이가 유의한가?
둘째, 명사구 수식언 유무 및 위치에 따른 비전형적 구문구조 산출률에서 청년층과 노년층의 집단 간 차이가 유의한가?
셋째, 교육년수 및 인지 기능 관련 변수 중 명사구 수식언 유무 및 위치에 따른 비전형적 구문구조 산출률을 유의하게 예측하는 변수는 무엇인가?
연구방법
연구대상
본 연구는 정상 성인을 기준으로 청년층 50명, 노년층 50명 총 100명의 참여로 이루어졌다. 청년층은 만 20-40세, 노년층은 만 60-80세로 집단을 구분하였다. 본 연구는 모든 피험자들에게 실험 내용에 대한 안내를 한 후 동의서에 서명을 받았으며, 이화여자대 학교 생명윤리위원회의 승인을 받아 진행하였다(IRB No. EWHA201904-0028-01). 두 집단 모두 서울 및 경기도 소재에 거주하는 대상으로 공통적인 선별 기준은 다음과 같다.
(1) 한국어를 모국어로 사용하며, (2) 교육년수가 9년 이상이며, (3) 언어 및 인지적 문제가 없고 신경학적 손상, 발달적 병력이 보고되지 않으며, (4) 한국형 간이 정신상태검사(Korean-Mini Mental State Examination, K-MMSE; Kang, 2006) 점수가 연령 및 교육년수를 고려했을 때 16%ile 이상으로 정상범위에 해당하며, (5) 과제를 수행하는데 필요한 시각 및 청각에 이상이 없고, (6) 글자를 읽고 이해하는데 문제가 없는 자로 선정하였다.
노년층의 경우 추가적으로 서울신경심리검사 2판(Seoul Neuropsychologic Screening Battery-II [SNSB-II]; Kang, Chang, & Na, 2012)의 하위검사인 서울언어학습검사(Seoul Verbal Learning Test, SVLT)를 실시하였으며, 연령 및 교육년수를 고려했을 때, 16%ile 이상인 대상자를 선별하였다.
집단 간 교육년수에서 유의미한 차이가 있는지 살펴보기 위해 각각 독립표본 t-검정(two-independent sample t-test)을 실시하였다. 그 결과, 집단 간 교육년수는 통계적으로 유의한 차이가 없었다. 집단 별 피험자의 기술통계 정보는 Table 1에 제시하였다.
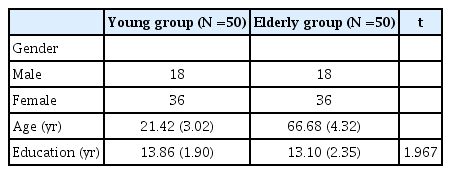
Demographic information on participants
실험과제
문장 산출 과제
본 연구에서 사용한 문장 산출 과제는 Yamashita와 Chang (2001)의 실험 1 과제를 수정 및 보완하였다. Yamashita와 Chang (2001)은 명사구 수식언의 유무 및 위치에 따른 문장 산출 형태를 살펴보는 과제로 흩어진 문장 구성요소들을 보고 간단한 숫자 계산을 한 후 15초 후 문장을 회상하는 방식으로 과제를 구성하였다.이 과제는 명사구 수식언의 유무 및 위치에 따라 문장 구성요소들을 어떻게 배열하는지 알아보는 과제이다.
실험 문장 유형은 총 세 가지로 명사구 수식언의 유무 및 위치에 따라 수식언 없이 ‘주어+목적어+서술어’의 형태로 구성된 ‘수식언이 없는 문장(No modifier)’과 수식언이 꾸며주는 문장 성분 여부에 따라 각각 ‘수식언의 주어수식 문장(Long-subject)’과 ‘수식언의 목적어수식 문장(Long-object)’이다. 본 연구에서는 Yamashita와 Chang (2001)의 실험 문장을 한국어로 재구성한 것으로 동일한 구문구조를 사용하였으나, 노화에 따라 작업기억 능력이 쇠퇴한 노년층이 대상 군에 속하는 것을 고려하여 간단한 숫자 계산 과정을 제외하는 것으로 실험 과정을 수정하였다.
‘수식언이 없는 문장’은 ‘주어+목적어+서술어’의 3어절 형태이며, ‘수식언의 주어수식 문장’과 ‘수식언의 목적어수식 문장’은 2어절로 구성된 관형사 구가 각각 주어와 목적어를 수식하는 5어절 형태이다. 또한 서술어는 모두 타동사이며, ‘수식언이 없는 문장’의 음절 수 범위는 8-12음절, 관형사구의 음절 수 범위는 5-7음절로 통제하였다. 문장에 사용된 모든 단어들은 국립국어원의 세종말뭉치 통계(National Institute of Korean Language, 2010)에서 빈도 수를 고려하여 빈도 수 100 이상의 고빈도와 최고빈도의 단어로 선정하였다. 모든 실험 문장의 주어는 문장에서 행위자(agent)의 의미역을 할당하며, 목적어는 대상(theme)의 의미역을 할당하였다. 한편, 수식언으로 사용된 관형사구는 두가지 형용사가 연결어미(-고)로 대등하게 연결된 형태이다.
실험에 사용된 문장은 각 유형 별로 24문장씩 총 72문장이다. 목표 문장은 문장 성분 단위로 분리하여 화면에 제시하되, 순서 효과를 줄이기 위해 72개의 문장이 무작위 순으로 제시되었으며, 위치 효과를 줄이기 위해 주어 및 목적어 위치 역시 문장 마다 무작위로 배역하였다. 단, 서술어의 경우 화면 왼쪽 상단에 고정하여 서술어로 인한 문장 산출 오류를 줄이고자 하였다. 예를 들어 ‘동생이 즐겁고 유쾌한 친구를 사귀다’라는 문장에서 ‘즐겁고 유쾌한 친구를’은 오른쪽 하단에 두고 ‘동생이’는 오른쪽 상단에 두며, ‘사귀다’는 왼쪽 상단에 고정하는 방식으로 제시하였다. 순서 효과와 위치 효과를 줄이기 위해 세 가지로 형태로 구성하여 피험자 별로 다르게 제공하였으며, 같은 단어로 구성된 문장 유형이 5회 이내에 다시 제시되지 않도록 배열하였다.
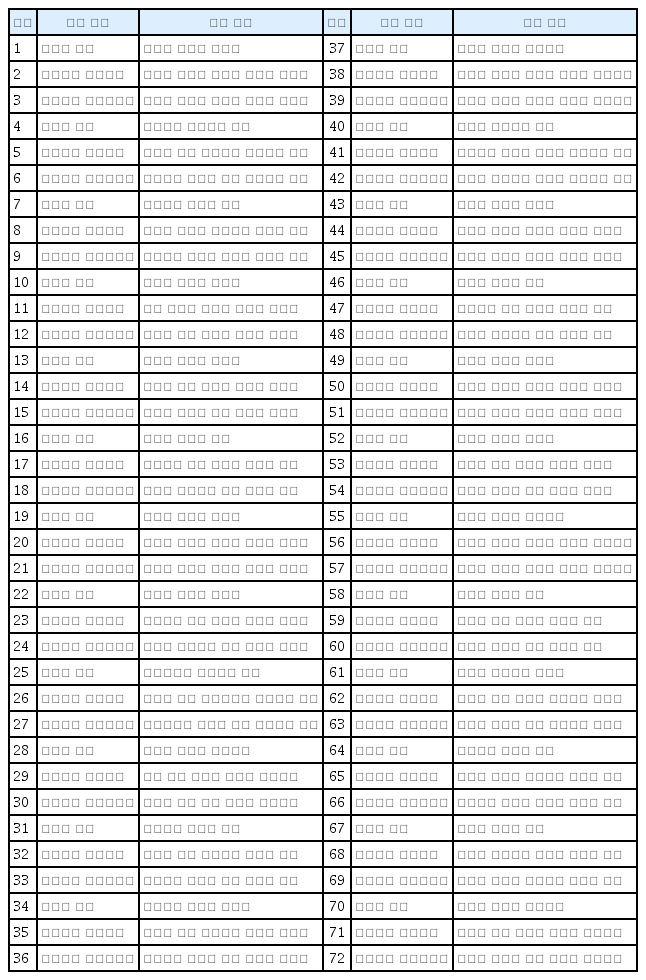
문장 산출 과제의 예시는 Table 2와 Figure 1과 같다. 문장 산출 과제의 목표 문장 목록은 Appendix 1에 제시하였다.

An example of sentence production task

An example of stimuli.
작업기억 과제
본 연구에서 사용된 작업기억 과제는 총 두 가지 유형으로 먼저 한국판 웩슬러 지능검사(Korean-Wechsler Adult Intelligence Scale; Hwang, Kim, Park, Choi & Hong, 2012)의 숫자 거꾸로 따라 말하기(digit backward, DB)를 사용하였고, Sung (2011)의 두가지 과제 중 단어 폭 단어 거꾸로 따라말하기(word backward, WB)를 사용하였다. 숫자 바로 따라말하기(digit forward, DF)와 Sung (2011)의 단어 바로 따라말하기(word forward, WF)과제는 작업기억 과제에 포함하지 않았는데, 이는 Baddeley (1990)에서 작업기억이 정보의 저장과 조작이 함께 이뤄지는 경우를 지칭하기 때문이다. 즉, 숫자 바로 따라말하기 검사와 단어 바로 따라말하기 검사는 작업기억의 하위 기능 중 저장기능에만 해당하기에 저장기능과 처리기능을 동시에 요구하는 거꾸로 따라말하기 과제 두가지만 이용하고자 했다.
따라서 본 연구에서는 총 두가지 작업기억 과제를 실시한 후 각 항목별 점수를 합산한 점수를 작업기억 과제의 총합 점수(Working memory sum, WM SUM)로 지칭하고 인지 기능 관련 변수로 보고자 하였다.
장기기억 과제
본 연구에서는 서울언어학습검사(Seoul verbal learning test, SVLT)를 장기기억 과제로 사용하였다. SVLT는 다시 즉각 회상(immediate), 지연 회상(delay), 재인(Recognition)검사로 구성되어 있다. 인지 관련 변수는 정보의 저장 및 인출과 관련되므로 본 연구에서는 즉각 회상 과제와 지연 회상 과제만을 장기기억 과제로 사용하였다. 즉각 회상 과제와 지연 회상 과제의 진행방법은 다음과 같다.
먼저 즉각 회상 과제는 총 3회에 걸쳐 실시되며, 실험자는 과제 설명을 한 후 2-3음절로 구성된 12개의 단어를 2초에 하나씩 일정한 속도로 불러준다. 실험자가 12개의 단어를 모두 부르면 피험자는 순서에 상관없이 기억나는 단어들을 구어로 산출한다. 만약 피험자가 반응이 없을 경우 응답촉구를 할 수 있으며, 기억 회상을 마치면 1차 시행 방식과 동일하게 2차, 3차 즉각 회상을 유도한다. 본 연구에서는 즉각 회상 과제의 1-3회차 점수를 합산한 것을 즉각 회상 과제의 점수로 칭하였다.
지연 회상 과제는 즉각 회상 과제를 실시한 후 20분의 시간이 흘렀을 시점에 시행하는 것으로, 피험자에게 ‘얼마 전에 제가 낱말을 여러 개 불러 드리고 여러 번 외워 보시라고 한 적이 있었죠? 그 때 무슨 낱말이 있었나요?’라고 지시하여 즉각 회상 과제에서 학습된 단어들이 20분이 지나도 장기기억 속에 저장이 되어 있으며 인출이 되는지 확인한다. 지연 회상 역시 화자가 반응이 없으면 응답을 촉구할 수 있다.
실험절차
본 실험에 사용된 노트북은 SAMSUNG제품이며 모델명은 NT900X3L이다. 모니터 해상도는 1,920×1,080, 13인치 크기다. 실험 자극은 Microsoft사의 PowerPoint 2016으로 자체적으로 제작하였으며, 바탕화면은 흰색으로 글씨는 검정색으로 구성하였다. 글씨체는 맑은 고딕, 글씨크기는 54 point로 고정하였으며, 서술어(동사)의 위치는 왼쪽 상단(가로 위치 3.61 cm, 세로 위치 4.02 cm)로 고정하였다. 그 외의 문장 구성요소들은 오른쪽 상단(가로 위치 18.84 cm, 세로 위치 4.02 cm)과 왼쪽 하단(가로 위치 3.61 cm, 세로 위치 10.18 cm), 오른쪽하단(가로위치 18.84 cm, 세로위치 10.18 cm) 중 한 곳에 제시된다.
본 과제를 시작하기 전 실험자는 연습 문제를 통해 실험 방법을 설명하고 피험자가 충분히 방법을 숙지할 수 있도록 하였다. 실험 방법에 대한 설명은 ‘지금부터 화면에 여러 가지 문장 구성요소들이 흩어져서 등장할 거예요. 시간을 충분히 드릴 테니 의미를 생각하며 문장으로 만들어서 기억을 해주세요. 충분히 기억을 하셨다 생각이 드시면 스티커가 붙어있는 키보드를 눌러주세요. 그러면 아무것도 없는 빈 화면이 등장할 겁니다. 빈 화면은 일정 시간이 지나면 자동으로 넘어가게 되는데, 화면이 넘어가며 글자가 나타나면 전에 보았던 글자들을 회상하여 문장으로 만들어서 말씀해주세요.’로 제시하였다. 키보드 스페이스바에는 스티커를 부착해 시각적으로 눈에 띄게 하여 컴퓨터 조작이 비교적 익숙하지 않은 노년층도 쉽게 사용할 수 있도록 하였다.
본 과제가 진행되면 피험자가 산출한 모든 발화는 노트북에 탑재된 Microsoft사의 음성 녹음기(ver.10.1909.2812.0)로 녹음하여 저장하였다. 피험자 별로 다소 차이는 있으나, 선별검사와 본 실험 시간을 모두 포함하여 피험자별 평균 소요시간은 청년층의 경우 50-60분, 노년층의 경우 90-100분이었다. 실험 과정은 Figure 2와 같다.

Schematic paradigms of experimental procedures.
자료분석
실험자는 각 피험자의 발화를 전사한 후 분석하였다. 간투사 및 자가 수정을 포함하여 피험자의 모든 발화는 피험자 및 목표 문장에 따라 전사되었으며, 회상하지 못하고 넘어갈 경우 ‘무반응’으로 표시하고 오반응으로 간주하였다.
정반응률
정반응은 목표 문장을 한국어의 기본 어순인 ‘주어+목적어+서술어’의 순서대로 배열한 문장으로 목표 문장의 구성요소들을 그대로 산출한 경우에 1점, 한국어의 기본 어순을 지키지 않은 비전형적 문장 및 문장 구성요소를 생략하거나 대치, 삽입 등 오류를 보인 경우는 오반응으로 0점으로 계산하였다. 정반응률(%)은 백분율로 계산하였는데, 수식언의 유무 및 위치 조건 별로 정반응 한 문장 수를 조건별 전체 문장 수로 나누고 100을 곱하여 도출하였다.
비전형적 구문구조 산출률
비전형적 구문구조 산출률은 수식언 유무 및 위치 유형별로 목표 문장의 내용에서 벗어나지 않았으나 문장 배열이 ‘목적어+주어+서술어’로 산출한 문장의 수를 센 후 각 유형별 전체 문항 수로 나누어 100을 곱하여 산출하였다. 즉, 각 문장 유형 별로 ‘목적어+주어+서술어’의 형태로 산출한 문장에는 1점을, 한국어의 어순을 따르는 문장이나 목표 문장의 내용에서 벗어나 오류를 보인 문장은 0점으로 점수를 부여하였다. 비전형적 구문구조로 문장을 산출하는예시는 Table 3과같다.
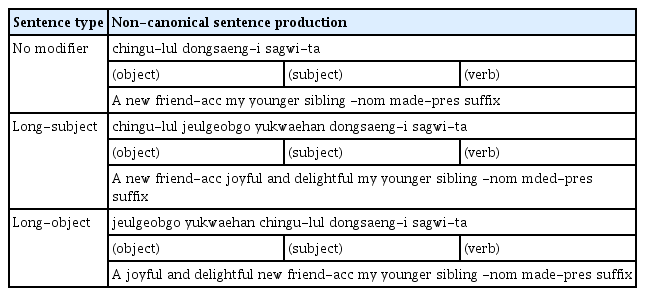
An example of non-canonical sentence production
자료의 통계적 처리
자료의 통계적 처리는 SPSS 22.0 for Windows (Inc., IL, USA) 프로그램을 사용하여 분석하였다. (1) 명사구 수식언 유무 및 위치(수식언 없음 및 수식언의 주어수식 및 수식언의 목적어수식)에 따른 문장 산출에서 집단(청년층과 노년층) 간 정반응률 차이가 유의한지 알아보기 위해 이원혼합분산분석(two-way mixed ANOVA)을 실시하였다. 연령으로 상이하게 구분된 집단은 피험자 간 요인(between subject factors)이며, 명사구 수식언 유무 및 위치에 따른 조건은 피험자 내 요인(within subject factors)으로 한다. 이원혼합분산분석 실시 후, 주효과가 유의할 경우 사후검정으로 Bonferroni를 이용하여 사후검정을 실시하였다. 또한 통계 분석에서 구형성 가정을 만족하지 않은 경우에는 Greenhouse-Geisser correction한 p-value를 제시하였다. (2) 명사구 수식언 유무 및 위치(수식언 없음 및 수식언의 주어수식 및 수식언의 목적어수식)에 따른 비전형적 구문구조 산출률에서 집단(청년층과 노년층) 간 차이가 유의한지 알아보기 위해 이원혼합분산분석(two-way mixed ANOVA)를 실시하였다. 이때, 연령으로 상이하게 구분된 집단은 피험자 간 요인(between subject factors)이며, 명사구 수식언 유무 및 위치에 따른 조건은 피험자 내 요인(within subject factors)으로 한다. 이원혼합분산분석 실시 후, 주효과가 유의할 경우 사후검정으로 Bonferroni를 이용하여 사후검정을 실시하였다. 또한 이차상호작용이 유의할 경우, 사후 검정으로 MMATRIX와 LMATRIX 명령문을 사용하여 이차상호작용의 원인이 무엇인지 명시하고자 하였다. 마지막으로 통계 분석에서 구형성 가정을 만족하지 않은 경우에는 Greenhouse-Geisser correction한 p-value를 제시하였다. (3) 교육년수 및 인지 기능 관련 변수 중 명사구 수식언 유무 및 위치에 따른 비전형적 구문구조 산출률을 유의하게 예측하는 변수가 무엇인지 알아보기 위해 단계적 회귀분석(Stepwise regression analysis)을 실시하였다. 단계적 회귀분석은 교육년수, 인지관련 변수 순서로 진행되었으며, 인지관련 변수는 K-MMSE, 작업기억 점수의 총합, 장기기억 과제 점수 순서로 대입되었다.
연구결과
명사구 수식언 유무 및 위치에 따른 문장 산출에서 집단 간 정반응률 차이
명사구 수식언 유무 및 위치에 따른 문장 산출에서 두 집단의 정반응률을 비교한 결과 명사구 수식언 유무 및 위치에 따른 모든 문장 유형에서 노년층의 정반응률이 청년층보다 낮았다. 문장 유형 별로는 수식언의 목적어수식 문장에서 두 집단 모두 가장 낮은 정반응률을 보였으며, 그 다음으로 수식언의 주어수식 문장, 수식언이 없는 문장 순이었다. 이에 대한 기술 통계는 Table 4에 제시하였고, 분석결과는 Figure 3과같다.
Descriptive statistics of production ratio (%) of non-canonical structures
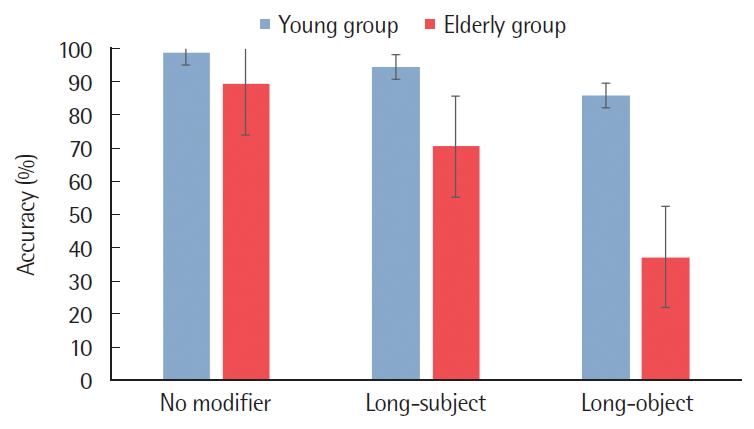
Accuracy of sentence production task for each sentence type (Error Bar=SD).
명사구 수식언 유무 및 위치에 따른 정반응률에서 집단 간 차이가 있는지 알아보기 위해 집단 간 요인으로 청년층과 노년층을 두고, 집단 내 요인으로 명사구 수식언의 유무 및 위치를 두고 이원혼합분산분석(Two-way mixed ANOVA)을 실시하여 주효과 및 상호작용 효과를 검증하였다. 그 결과 청년층과 노년층 간의 주효과가 통계적으로 유의하였다(F(1, 98)=117.28, p<.001). 즉, 노년층의 정반응률이 청년층의 정반응률 보다 유의하게 낮았다. 명사구 수식언 유무 및 위치 유형에 대한 주효과 역시 통계적으로 유의하였다(F(2, 196)=175.79, p<.001). 이에 Bonferroni 사후검정을 통해 어떤 유형의 차이로 인한 결과인지 도출하였다. 확인 결과, 수식언의 주어수식 문장과 수식언의 목적어수식 문장에서의 정반응률이 수식언이 없는 문장에서보다 유의하게 낮았고(p<.001), 수식언의 목적어수식 문장에서의 정반응률이 수식언의 주어수식 문장에서의 정반응률 보다 유의하게 낮았다(p<.001). 다음으로 명사구 수식언 유무 및 위치에 대한 집단 간 이차상호작용이 통계적으로 유의하였다(F(2, 196)=63.41, p<.001). 이에 MMATRIX와 LMATRIX 명령문을 사용하여 사후검정을 한 결과, 수식언의 목적어수식 문장에서 집단 간 정반응률 차이가 수식언이 없는 문장과 수식언의 주어수식 문장에서의 정반응률 차이보다 유의하게 컸다(F(1, 98)=109.93, p<.001; F(1, 98)=43.43, p<.001). 또한 수식의 주어수식 문장에서의 집단 간 정반응률 차이가 수식언이 없는 문장에서의 정반응률 차이보다 유의하게 컸다(F(1, 98)=22.88, p<.001).
명사구 수식언 유무 및 위치에 따른 비전형적 구문구조 산출률에서 집단 간 차이
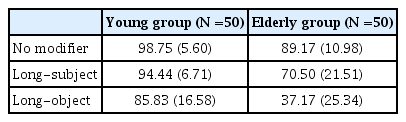
명사구 수식언 유무 및 위치에 따른 문장 산출에서 두 집단의 비전형적 구문구조 산출률을 비교한 결과, 모든 문장 유형에서 노년층의 비전형적 구문구조 산출률이 청년층보다 높았다. 문장 유형 별로는 수식언의 목적어수식 문장에서 두 집단 모두 가장 높은 비전형적 구문구조 산출률을 보였으며, 그 다음으로 수식언이 없는 문장, 수식언의 주어수식 문장 순이었다. 이에 대한 기술 통계는 Table 5에 제시하였으며, 분석결과는 Figure 4와 같다.

Descriptive statistics of non-canonical structure ratio (%)
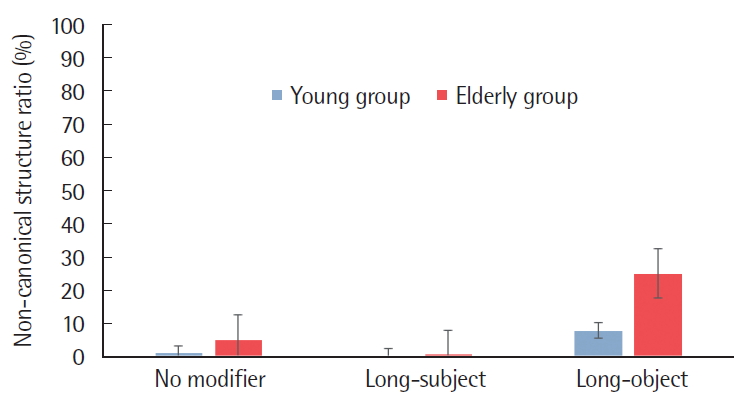
Ratio of non-canonical structures in the sentence production task (Error Bar=SD).
명사구 수식언 유무 및 위치에 따른 비전형적 구문구조 산출률에서 집단 간 차이가 있는지 알아보기 위해 집단 간 요인으로 청년층과 노년층을, 집단 내 요인으로 명사구 수식언의 유무 및 위치를 두고 이원혼합분산분석(Two-way mixed ANOVA)을 실시하여 주효과 및 상호작용 효과를 검증하였다. 그 결과 청년층과 노년층 간의 주효과가 통계적으로 유의하였다(F(1, 98)=25.71, p<.001). 즉, 노년층의 비전형적 구문구조 산출률이 청년층의 것보다 유의하게 높았다. 명사구 수식언 유무 및 위치 유형에 대한 주효과 역시 통계적으로 유의하였다(F(2, 196)=85.70, p<.001). 이에 Bonferroni 사후검정을 통해 어떤 유형의 차이로 인한 결과인지 도출하였다. 확인 결과, 수식언의 목적어수식 문장과에서의 비전형적 구문구조 산출률이 수식언이 없는 문장과 수식언의 주어수식 문장의 것보다 유의하게 높았고(p<.001), 수식언이 없는 문장에서의 비전형적 구문구조 산출률이 수식언의 주어수식 문장의 것보다 유의하게 높았다(p<.001). 다음으로 명사구 수식언 유무 및 위치에 대한 집단 간 이차상호작용이 통계적으로 유의하였다(F(2, 196)=22.88, p<.001). 이에 MMATRIX와 LMATRIX 명령문을 사용하여 사후검정을 한 결과, 수식언의 목적어수식 문장에서 집단 간 비전형적 구문구조 산출률 차이가 수식언이 없는 문장과 수식언의 주어수식 문장에서의 집단 간 비전형적 구문구조 산출률 차이보다 유의하게 컸다(F(1, 98)=20.84, p<.001; F(1, 98)=25.82, p<.001). 또한 수식언이 없는 문장에서의 집단 간 비전형적 구문구조 산출률 차이가 수식언의 주어수식 문장에서의 집단 간 비전형적 구문구조 산출률 차이보다 유의하게 컸다(F(1, 98)=10.46, p<.01).
명사구 수식언 유무 및 위치에 따른 비전형적 구문 산출률에 영향을 미치는 요인
문장 산출 과제에서 명사구 수식언 유무 및 위치에 따른 비전형적 구문 산출률을 예측할 수 있는 변수를 알아보고자 단계적 회귀분석(stepwise regression analysis)을 실시하였다. 단계적 회귀분석은 청년층과 노년층 집단별로 각각 분석하였으며, 예측 변인으로는 교육년수와 인지 기능 관련 변수인 K-MMSE(Kang, 2006), 작업기억 총점, 서울언어학습검사(Kang & Na, 2003) 중 즉각 회상 과제와 지연 회상 과제의 점수 각각을 독립 변인으로 설정하였다. 종속변인에는 명사구 수식언 유무 및 위치에 따라 수식언 없는 문장, 수식언의 주어수식 문장, 수식언의 목적어수식 문장에서의 비전형적 구문구조 산출률이다.
그 결과, 어떠한 예측 변인도 청년층의 명사구 수식언 유무 및 위치에 따른 비전형적 구문구조 산출률을 유의하게 예측하지 않는 것으로 나타났다. 다시말해, 교육년수 및 인지기능 관련 변수는 청년층의 수식언 유무 및 위치에 따른 문장 유형별 비전형적 구문구조 산출률을 유의하게 예측해주지않는 것으로 나타났다.
노년층의 경우에도 수식언이 없는 문장과 수식언의 주어수식 문장에서의 비전형적 구문구조 산출률이 투입된 회귀 모형에서 비전형적 구문구조 산출률을 예측하는 유의한 변수는 존재하지 않았다. 그러나 수식언의 목적어수식 문장에서의 비전형적 구문구조 산출률은 유의한 예측변수가 드러났는데, Table 6에 제시한 것처럼 숫자 및 단어 작업기억 과제의 총점(β=3.900), 서울언어학습검사 과제 중 지연회상 과제 점수(β=-2.970) 순서로 투입된 회귀 모형이 통계적으로 유의하였다(F(2, 49)=11.79, =.304, p<.01). 이는 작업기억 과제와 지연 회상 과제에서의 수행도가 노년층의 명사구 수식언의 목적어수식 문장에서의 비전형적 구문구조 산출률을 30.4% 예측하였다. 또한 작업과제의 총점(β=3.382)이 투입된 회귀 모형이 통계적으로 유의하였다(F(1, 49)=9.64, =.197, p<.01). 이는작업기억 과제의 수행도가 노년층의 명사구 수식언의 목적어수식 문장에서의 비전형적 구문구조 산출률을 19.7% 예측하였다.
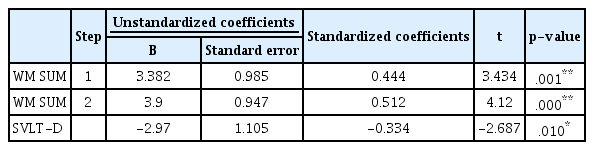
The result of stepwise regression analysis to predict non-canonical structure ratio of elderly group
논의 및 결론
본 연구는 한국어가 모국어인 정상 청년층과 정상 노년층을 대상으로 문장 산출 과제를 활용하여 명사구 수식언의 유무 및 위치에 따른 과제 수행력을 살펴보고 이어서 문장 유형 별로 비전형적 구문구조 산출률을 확인하였다. 마지막으로 인지 관련 변수 중 문장 유형별 비전형적 구문구조 산출률을 가장 잘 예측해주는 변인을 살펴보았다.
본 연구 결과, 노년층은 문장 산출 과제 수행 시 명사구 수식언의 유무 및 위치에 따른 모든 문장 유형에서 청년층에 비해 어려움을 보였다. 특히 수식언이 없는 문장에서의 수행력보다 수식언이 있는 두 문장 유형에서 수행도가 유의하게 낮았으며, 주성분인 주어와 목적어 사이에 수식언이 위치하는 수식언의 목적어수식 문장에서 가장 큰 어려움을 보였다. 이러한 결과는 문장의 길이가 길고, 주어와 목적어 사이에 관형사구가 들어 간 것이 원인이 되어 수행력이 떨어진것이다. 이는 수식언등으로 문장의 길이가 길어져요구되는 작업기억 용량이 늘고, 주어와 목적어 사이에 부속성분인 관형사구가 위치함에 따라 접근성이 떨어지게 되면 인지적인 부담이 증가해 문장을 처리하는데 상당한 노력이 필요하다는 선행연구의 결과와 맥락을 같이한다(Yamashita & Chang, 2001; Nam & Hong, 2013). 즉, 본 연구에 따르면 노화로 인해 인지적 처리 능력이 둔화된 노년층은 문장의 길이가 길고, 수식언의 목적어수식 문장에서 청년층에 비해 큰 어려움을 보인 것으로 해석할 수 있다.
문장의 길이가 길어지고, 접근성이 떨어짐에 따라 인지적 부담이 늘어나게 되면 사람들은 문장의 구성 성분 중 주성분 간의 거리를 좁힘으로써 처리 부담을 덜고자 하는데(Nam & Hong, 2013; Stalling, Maryellen, & Padraig, 1998), 이는 명사구 수식언의 유무 및 위치에 따른 비전형적 구문구조 산출률에서 확인할 수 있다. 명사구 수식언 유무 및 위치에 따른 문장 유형에서 가장 많은 비전형적 구문구조 산출률을 보인 문장 유형은 두 집단 모두 수식언의 목적어 수식 문장이었다. 이에 반해 수식언의 주어수식 문장과 수식언이 없는 문장에서는 비전형적 구문구조 산출률이 높지 않았다. 이는 선행 연구의 결과와 일치한다(Yamashita & Chang, 2001). 즉, 본 연구에 따르면 수식언의 목적어수식 문장은 주어와 목적어 사이에 관형사구가 위치하여 주어와 서술어 사이의 거리가 생기게 됨에 따라 문장 논항구조의 파악이 어려워지고 이에 처리 부담을 느낀 화자들은 어순 도치를 통해 처리 부담을 덜고자 하는 것이다. 다시 말해, ‘즐겁고 유쾌한 친구를 동생이 사귀다’와 같이 문장을 산출함으로써 수식언으로 길어진 목적어구를 주어구 앞에 선치하고 서술어와 주성분들 간 거리를 좁혀 처리의 경제성이나 효율성을 높이고자 하는 것이다.
본 연구에서 노년층이 청년층에 비해 명사구 수식언 유무 및 위치에 따른 문장 유형에서 비전형적 구문구조를 더 많이 산출한다는 것은 수식언의 유무 및 위치와 연령 집단에 대한 이차 상호작용 결과로 해석할 수 있다. 문장 산출 과제에서 노년층은 청년층보다 낮은 정반응률을 보였는데, 수식언이 있는 조건의 문장에서 보다 낮은 수행력을 보였다. 이는 수식언이 있는 문장은 없는 문장보다 문장의 길이가 길고, 수식언으로 인해 주어와 서술어의 거리 격차가 생김으로써 노년층이 문장을 처리하는데 있어서 인지적 부담이 증가하게 된다. 특히 수식언의 목적어수식 문장은 수식어구가 주어와 목적어 사이에 위치함으로써 구문구조 파악에 어려움을 주게되는데, 이에 수식언을 포함한 목적어구를 주어 앞으로 선치 시킨 비전형적 구문구조를 산출한 것으로 해석할 수 있다.
이러한 결과는 선행 연구에서 수학 계산으로 인지적 부담을 높인 상황에서의 청년층 결과와 유사한데, 이는 숫자 계산과 같은 인지적 부담을 높이는 과제가 포함되지 않아도 노년층에게 있어서 수식언으로 인해 길어진 문장 형태를 부호화 및 학습을 통해 저장하고 일정 시간 이후 기억된 정보를 인출하여 산출하는 일련의 과정이 청년층에 비해 덜 유연한 것으로 해석할 수 있을 것이다.
교육년수 및 인지 관련 변수 중에 수식언의 목적어수식 문장에서의 노년층의 비전형적 구문구조 산출률을 유의하게 예측해주는 변수는 작업기억 과제의 총 점수와 지연 회상 과제의 점수였다. 작업기억 과제 점수는 목적어수식 문장에서의 노년층의 비전형적 구문구조 산출률을 19.7% 예측하였고, 작업기억 과제 점수 및 지연 회상 과제의 점수에 관해서는 30.4%의 예측력을 보였다. 반면 즉각 회상 과제와 교육년수는 비전형적 구문구조 산출률을 예측하기 어려웠다. 또한 회귀 모형에서 작업기억 과제의 점수는 비전형적 구문구조 산출률과 양의 상관관계를, 지연 회상 과제의 경우는 음의 상관을 보였다. 즉, 본 실험에서 작업기억이 높은 참가자일수로 더 많은 비전형적 구문구조를 산출하였고, 지연 회상 과제의 점수가 낮을수록 비전형적 구문구조 산출률이 높았음을 의미한다.
본 실험에서 피험자들은 화면에 흩어진 문장 구성요소들을 각자의 방식으로 저장을 하고 일정 시간 후 재구성하여 인출하는 과정을 거쳤다. 그런데 지연 회상 과제의 점수가 낮을수록 저장 후 인출을 하는 일련의 과정에서 인지적 부담감이 큰 것으로 볼 수 있다. 따라서 지연 회상 과제의 점수가 낮은 피험자일수록 과제 수행에 대한 부담감이 높았고 이로 인해 하나의 전략으로 비전형적 구문구조를 산출한 것으로 볼 수 있을 것이다. 반면 작업기억 능력이 높을수록 비전형적 구문구조 산출률이 높은 것은 이러한 영역 최소화 전략을 이용하여 문장 처리 과정의 부담을 덜고 오반응률을 줄이려는 전략도 작업기억 능력이 없으면 유연하게 사용하지 못하는 것으로 해석해볼 수 있다. 즉, 작업기억 능력이 있어야 흩어진 문장을 기억하였다 일정시간 후 인출하는 과정을 유연하게 대처할 수 있는 것으로 보인다. 이러한 결과는 흩어진 문장 구성 요소들을 배열하여 문장으로 만들고 기억을 했다가 일정 시간 후 회상하는 작업에 작업기억 능력과 지연 회상 능력이 영향을 끼칠 수 있다는 것을 의미한다.
본 연구에서는 기존 연구에서 다루지 않았던 연령에 따라 구분 지은 집단 간 차이를 알아보았다는데 의의가 있다. 흥미로운 것은 선행연구에서 청년층을 대상으로 한 실험 과정에 인지적 부담을 늘리기 위해 숫자 계산이라는 언어 외적인 방해요소를 삽입한데 반해, 본 연구에서는 난이도를 고려해 이 언어 외적 방해요소를 제거했음에도 불구하고 노년층에서 선행연구와 유사한 비전형적 구문구조 산출률이 나타난 점이다. 이는 노년층에게는 문장 산출 과정에서 언어 외적인 방해요소가 없더라도 이미 작업기억 및 장기기억 능력 등 인지적인 능력에서의 노화가 진행되어 길고 복잡한 문장 길이 자체로 충분히 부담감이 높을 수 있다는 것을 의미한다.
따라서 본 연구가 임상적으로 시사하는 바는 다음과 같다. 첫째, 노화는 작업기억 및 장기기억 능력의 저하를 야기하며 이러한 기억력의 감퇴는 문장 산출 과정에 영향을 끼칠 수 있다. 둘째, 본 연구에서는 정상 노화 과정에서 수식언 등으로 인해 문장의 길이가 늘어나고 접근성이 떨어지게 되면 화자는 주성분과 서술어 간의 거리를 응집시킴으로써 인지적 부담을 줄이고자 하는 전략을 사용한다는 것을 확인할 수 있다. 이는 향후 다른 신경학적 병리군과 비교한다면 정상 노화 집단과 언어 신경학적 병리군 집단을 구분할 수 있는 기준 체계를 성립할 수 있을 것으로 사료된다. 셋째, 본 연구결과를 바탕으로 미루어 보았을 때, 문장 성분의 길이 및 논항구조는 문장을 처리하는 과정에 상당한 영향을 미치는 것으로 판단된다. 그러므로 임상에서 문장 자극을 사용하거나 환자가 문장을 산출하도록 유도할 때 문장 성분의 길이 및 논항구조의 특성을 충분히 고려하여 자극으로 인한 부담감을 줄이고 경제성, 효율성을 고려한 자극 선정이 중요할 것이다.
본 연구의 제한점 및 후속 연구를 위한 제언은 다음과 같다. 첫째, 본 연구에서 피험자를 모집할 당시 청년층의 경우 만 20-40세, 노년층의 경우 60-80세 기준으로 두었다. 그러나 청년층의 연령 분포는 20대에 집중되어 중장년층을 포함하지 않았다. 문장의 논항구조에 따라 느끼는 부담 정도에 따라 문장을 처리하고 산출하는 과정을 연령에 따라 변화하는 양상으로 확인하기 위해서는 다양한 연령대를 모집하여 후속 연구를 진행할 필요가 있다. 둘째, 피험자들의 발화를 분석할 시 문장 성분의 본래 의미에서 벗어난 반응을 오류로 제외시키고 분석하지 않았다. 그러나 오류로 제외한 문항 수가 연령에 따라 현저하게 차이가 나는 만큼 문장 산출 과제에서의 나타난 오류 문장을 분석 및 분류한다면 노화와 문장 처리에 관해 보다 깊이 있는 연구를 진행할 수 있을 것이다. 셋째, 본 연구에서 사용된 자극 문장은 ‘주어+목적어+서술어’로 구성된 논항구조에 관형어구를 각각 ‘주어’ 앞과 ‘목적어’ 앞에 배치한 문장으로 서술어의 자리 수가 두가지인 문장으로 한정하였다. 따라서 추후 연구에서는, 좀 더 다양한 논항구조의 문장을 실험 문장으로 설정할 필요가 있을 것이다. 마지막으로 본 연구에서는 교육년수와 작업기억, 장기기억 변수를 통해 피험자의 문장 산출 과제의 수행 능력과의 관계를 살펴보았으나 일부 과제로 국한되었다. 그러므로 추후 연구에서는 다른 인지 기능을 변수로 문장 산출 과제에서의 수행 능력과의 관계를 다양한 방향으로 살펴볼 필요가 있을 것이다.