잠재프로파일분석을 적용한 5-7세 아동의 언어능력에 따른 집단 탐색
Identifying the Latent Profiles of Language Ability in 5- to 7-Year-Old Children
Article information
Abstract
배경 및 목적
본 연구에서는 아동의 언어능력에는 하나의 패턴만 존재하는 것이 아니라 아동에 따라 다양한 언어능력 유형이 있을 것이라는 가정 하에 아동들의 수행 패턴을 바탕으로 유형을 구분하고자 하였다.
방법
아동 언어능력의 잠재집단 유형을 알아보기 위해서 5-7세 아동 147명이 참여했다. 아동의 언어능력에 따른 잠재집단의 수와 그 특성을 알아보기 위하여 언어의 차원을 구성한다고 여겨지는 음운, 의미, 구문 영역과 인지적 언어처리 영역인 처리용량과 처리속도 측면에서 아동의 언어능력을 살펴보았다. 각각의 영역은 음운인식 과제, 수용 어휘력 검사, 문장 따라말하기 과제, 비단어 따라말하기 과제 및 빠른 이름대기 과제로 측정했다.
결과
본 연구의 잠재프로파일분석 결과, 언어 과제에 기반해서 4개의 아동 언어능력 잠재집단이 도출되었다. 먼저 모든 과제에서 상대적으로 우수한 수행을 보였던 “우수 집단(15.7%)”, 모든 과제에서 평균 수준의 수행을 보였던 “평균 집단(65.8%)”, 그리고 모든 언어 과제에서 점수가 낮았으나, 상대적으로 빠른 이름대기 과제의 수행이 낮았던 “낮은 처리속도 집단(12.3%)”과 모든 언어 과제에서 점수가 낮았지만 특히 문장 따라말하기 과제의 수행이 낮았던 “낮은 구문능력 집단(6.2%)”이었다.
논의 및 결론
5-7세 아동 언어능력의 잠재집단은 크게 아동의 수행 수준에 따라 나누어지는 것처럼 보였다. 그러나 전체 언어 과제에서 상대적으로 낮은 수행을 보인 아동의 경우, 서로 다른 프로파일을 가진 잠재집단의 존재를 확인하였다.
Trans Abstract
Objectives
Classifying children into two language ability groups, with and without language impairment, may underestimate the number of groups with distinct language ability patterns. In this study, we tried to classify the children based on their language performance. The purpose of this study was to identify the number and characteristics of latent language ability groups in Korean children.
Methods
An unclassified sample of 147 Korean children aged 5 to 7 years participated in the study. Oral language skills in phonological (phonological awareness task), semantical (receptive vocabulary test), and syntactical (sentence repetition task) areas; language processing skills in processing capacity (non-word repetition task); and processing speed (rapid automatized naming task) were assessed. Latent profile analysis was conducted on the language measures.
Results
Results indicated that a four-group model best represented the data, characterized by high performance in one group (15.7%), average skills in another group (65.8%), low processing speed in a third group (12.3%), and low grammaticality in a fourth group (6.2%).
Conclusion
The latent profiles of language ability in Korean children seemed to be largely divided according to their level of language performance. However, in the group of children with low performance, the existence of different profiles was identified. This suggests that children with low performance may have difficulties learning language for two reasons: difficulties with either grammar or processing speed. Thus, assessing language abilities without testing both areas could potentially lead to misdiagnosis.
인간의 언어는 매우 복잡한 시스템으로 서로 다른 영역(음운, 의미, 구문 등)으로 구성된 다차원적인 체계라고 간주된다. 그러나 아동의 언어능력에 이러한 언어의 다차원성(multi-dimensionality)을 그대로 적용하는 것이 타당한지에 대하여는 아직 논의가 진행되고 있다. Leonard (2014)는 언어장애 아동의 문제가 하나의 영역에서의 어려움으로 깔끔하게 설명되지 않는 이유는 언어의 차원 구성과 실제 아동이 가진 언어능력의 차원 구성이 다르기 때문일 수 있다고 지적하였다(p. 53). 아동 언어능력의 차원성을 이해하는 것은 언어능력을 측정하는 검사도구의 타당도에 매우 중요할 것이다. 아동의 언어능력이 서로 다른 차원들로 구성되어 있다면 이 중 일부 영역에서만 아동의 언어능력을 측정하거나 혹은 아동의 하위 영역별 점수를 합산하여 통합 점수를 산정하는 방식은 개별 아동의 언어문제를 희석시키는 결과를 초래할 가능성이 있기 때문이다. 중재의 측면에서도, 아동 언어능력에 있어서 다양한 프로파일의 존재를 확인하는 것은 개별 아동에게 구체적이고도 적절한 중재 방법을 계획할 수 있게 할 것이다.
이러한 이유로 아동 언어능력의 차원성(dimensionality)은 국내 · 외 언어병리학 분야에서 빈번히 다루어지고 있는 연구주제 중 하나이나, 이것이 단일차원(단순히 언어능력 수준의 차이)이냐 다차원(서로 다른 프로파일을 가진 언어능력 집단의 존재)이냐에 대하여 선행연구결과가 일치하지 않는다(Bishop, North, & Donlan, 1995; Conti-Ramsden, Crutchley, & Botting, 1997; Leonard, 1987, 1991; Tomblin & Zhang, 1999).
아동의 언어능력 집단을 살펴본 일부 선행연구에서는 서로 다른 언어능력 유형이 나타난다는 것을 보여주었다(Bishop et al., 1995; Conti-Ramsden et al., 1997). 예를 들어, Bishop 등(1995)은 쌍둥이 중 적어도 한 명이 언어장애를 가진 7-10세 일란성 쌍둥이 63명과 이란성 쌍둥이 27명을 대상으로 Test of Reception of Grammar (TROG; Bishop, 1982), Wechsler Intelligence Scale for Children-Revised (WISC-R; Wechsler, 1974)의 이해 검사, 문장 따라말하기 검사(Semel, Wiig, & Secord, 1980), 낱말 찾기 검사(McKenna & Warrington, 1983; Renfrew, 1991) 등 표준화된 검사 4개를 시행하여 언어장애 아동들의 언어능력 집단을 살펴보았다. 그 결과, 아동들은 전반적 결함 아동(29%), 문장 따라말하기 결함 아동(41%), 그리고 문장 따라말하기와 낱말 찾기 결함 아동(29%)의 세 개의 언어 능력 집단을 구성했다. Conti-Ramsden 등(1997)의 연구 또한 서로 다른 프로파일을 가진 언어능력 집단을 확인했다. 연구자들은 7세 언어장애 아동 242명을 대상으로 세 가지 평가 방법(표준화된 검사, 언어치료사나 교사의 보고, 그리고 이 둘의 조합)을 사용했다. 표준화된 검사에서는 TROG와 어휘 이름대기, 수 개념 및 단어재인능력(British Ability Scales, BAS; Elliot, 1983), 조음능력(Goldman-Fristoe Test of Articulation; Goldman & Fristoe, 1986), 그리고 이야기 다시말하기를 통한 담화능력(Bus Story; Renfrew, 1991)을 검사했다. 연구자들은 이를 바탕으로 다음과 같은 6개의 집단을 나누었다: (a) 조음에는 문제가 없으나 구문/형태 영역에 어려움을 가진 아동 21.5%, (b) 음운 문제를 가진 아동 6.6%, (c) 조음과 음운 문제를 가진 아동 12.0%, (d) 역시나 조음과 음운 문제를 가졌으나, 세 번째 집단보다 전반적으로 나은 수행을 보이는 아동 9.5%, (e) 조음, 음운, 구문/형태 문제를 지닌 아동 34.7%, (f) 의미 및/혹은 화용 문제를 보이는 아동 10.3% (5.4%의 아동은 결측치 때문에 군집에 배정되지 않았다.) 그러나 두 연구 모두 언어장애 아동만을 대상으로 수행되어 선택 편향으로 인한 문제가 결과에 영향을 미쳤을 수 있다.
반면, 다른 연구자들은 아동의 언어능력이 서로 다른 하위집단으로 구별되기보다는 수행의 연속성으로 특징지어질 수 있다고 주장했다(Leonard, 1987, 1991; Tomblin & Zhang, 1999). 이들은 언어능력의 유형이 아니라 언어능력의 수준에 차이가 있다고 주장했다(Dollaghan, 2004; Tomblin & Zhang, 1999). 예를 들어, Tomblin과 Zhang (1999)에서는 정상 발달 아동, 언어장애 아동, 전반적 지체 아동을 포함한 1,933명의 유치원 아동을 대상으로 검사했다. 표준화된 언어검사도구(Test of Oral Language Development-Primary: 2, TOLD-P: 2; Newcomer & Hammil, 1988)로 아동의 구문 및 의미능력을 측정하였다. 연구자들은 언어 결함 수준에 따라 6개의 집단을 도출했으며, 집단은 의미와 구문 과제에서의 점수 차로 특징지어졌다. Dollaghan (2004)은 3-4세 언어장애 아동 및 일반 아동 620명을 대상으로 표준화된 검사, 언어 샘플 분석, 부모 보고 등을 사용했다. 3세 집단은 평균 발화 길이(Mean Length of Utterance, MLU)와 Language Development Survey (LDS; Rescorla, 1989; Rescorla & Achenbach, 2002), 4세 집단은 평균 발화 길이와 Peabody Picture Vocabulary Test-Revised (PPVT-R; Dunn & Dunn, 1981) 점수를 근거로 평가되었다. 연구결과, 두 연령 집단에서 모두 언어장애 아동과 일반 아동은 별개의 집단으로 구분되지 않았다. 그러나 아동 언어능력의 연속성을 지지한 두 연구 모두 실시한 언어 과제가 제한적이어서, 아동 언어능력을 구성하는 하위 영역을 보다 포괄적으로 살펴본 연구가 필요하다.
비록 많은 수의 연구들은 아니지만, 아동 언어능력의 차원 구성을 살펴본 최근 연구들은 기존 언어의 차원을 구성한다고 여겨지는 하위 영역(음운, 의미, 구문 등)과 더불어 인지적 언어처리능력을 고려해야 한다고 제안한다. 5-7세의 스페인어-영어 이중언어 아동을 대상으로 한 Kapantzoglou, Restrepo, Gray와 Thompson (2015)의 연구에서는 언어 샘플 분석과 함께 음운기억용량을 측정하기 위한 비단어 따라말하기 과제와 처리속도를 측정하기 위한 빠른 이름대기 과제를 사용하였다. 잠재프로파일분석 결과, 낮은 구문능력 집단, 낮은 음운기억용량 집단, 그리고 평균 집단의 세 집단으로 나뉘었다. 연구자들은 이러한 결과가 아동의 언어능력 평가 시 언어 영역과 함께 인지적 언어처리 영역을 고려하지 않는다면 잘못된 진단을 야기할 수 있음을 시사한다고 주장했다.
5-7세는 아동이 초등학교에 입학하는 시기로, 아동의 언어능력이 학교적응 및 문해능력과 직결되는 시기이다. 아동의 언어능력이 단일 영역이 아니라 여러 하위영역들로 구성되어 있다면, 언어검사에서 평균 점수가 같은 아동들이라 해도 이들의 언어능력이 동일하다고 보기는 어려울 것이다. 비슷한 수행을 보인 아동들을 하나의 집단으로 분류하여 그들의 공통된 특징을 파악한 후, 이를 기반으로 아동의 언어능력에 맞는 피드백을 제공해 줄 수 있다면 훨씬 더 효율적인 교육 및 중재 제공이 가능할 것이다. 또한 집단 수준에서 분석할 경우 개인 수준에서 분석하였을 때 발견하지 못했던 집단의 특징을 발견할 수 있다는 장점이 있다. 이러한 연구 필요성에 기반하여 본 연구에서는 5-7세 아동을 대상으로 이들이 각 언어 영역에서 보이는 과제 수행 프로파일에 따라 아동의 언어능력이 어떠한 하위집단으로 유형화할 수 있는지 잠재프로파일분석을 이용해 확인했다. 잠재프로파일분석은 현재 집단 내 잠재집단의 존재를 살펴보는 가장 정확하다고 알려진 통계 방법 중 하나이다(Collins & Lanza, 2010; Lubke & Muthén, 2007; Magidson & Vermunt, 2002; Pastor, Barron, Miller, & Davis, 2007).
본 연구의 연구문제는 다음과 같다.
첫째, 5-7세 아동의 언어능력을 유형화하기 위하여 최적의 잠재 집단 수는 몇 개인가?
둘째, 5-7세 아동 언어능력의 잠재집단별 언어 수행 특성은 음운인식 과제, 어휘 검사, 문장 따라말하기 과제, 비단어 따라말하기 과제 및 빠른 이름대기 과제를 기준으로 각기 어떠한 양상을 보이는가?
연구방법
연구대상
초등학교 입학 전 · 후 아동의 언어능력 프로파일 유형을 알아보기 위해서 5-7세 아동 147명을 대상으로 잠재프로파일분석을 실시하였다. 참여 아동은 서울 및 경기 지역에 거주하고, 부모 및 교사로부터 언어 및 인지 발달이 정상이고, 감각적, 정서적, 신경학적 문제가 없다고 보고된 아동들이었다. 전체 대상자 중 남아가 76명(51.7%), 여아가 71명(48.3%)이었고, 취학 여부에 따라 취학 전 아동이 87명(59.18%), 1학년 아동이 60명(40.82%)이었다.
검사환경 및 검사자
본 연구에서는 초등학교나 유치원, 어린이집에서 제공한 조용한 장소에서 검사자와 아동의 일대일 면접으로 검사를 진행하였으며, 검사의 순서는 무작위로 하였다. 검사는 언어병리학을 전공하는 대학원생에 의해 진행되었다. 검사자 훈련은 두 차례에 걸쳐 개별적으로 진행되었는데, 1차로 검사 내용 및 실시 방법에 대해 소개하고, 2차로 실제 검사를 실시한 후 이에 대한 피드백을 제공하는 방식으로 이루어졌다.
검사도구
본 연구에서는 아동 언어능력의 잠재프로파일 유형을 알아보기 위하여 구어 언어의 차원을 구성한다고 여겨지는 음운, 의미, 구문 영역과 인지적 언어처리 영역인 처리용량과 처리속도를 살펴보았다. 이를 위하여 선행연구를 통해 아동 언어능력 집단 구분을 위한 임상적 가능성이 확인된 음운인식 과제(Anthony, Davis, Williams, & Anthony, 2014; Foorman, Herrera, Petscher, Mitchell, & Truckenmiller, 2015; Tomblin, Zhang, Weiss, Catts, & Ellis Weismer, 2004), 수용 어휘력 검사(Anthony et al., 2014; Foorman et al., 2015; LARRC, 2017; Lonigan & Milburn, 2017), 문장 따라말하기 과제(Foorman et al., 2015; LARRC, 2017; LARRC, Yeomans-Maldonado, Bengochea, & Mesa, 2018)와 비단어 따라말하기 과제(Archibald & Joanisse, 2009; Dollaghan & Campbell, 1998; Estes, Evans, & Else-Quest, 2007; Gray, 2003), 빠른 이름대기 과제(Kail, 1994; Kail & Leonard, 1986; Kohnert, Windsor, & Ebert, 2009; Miller, Kail, Leonard, & Tomblin, 2001; Morgan, Srivastava, Restrepo, & Auza, 2009; Windsor & Hwang, 1999)를 사용하였다.
먼저 음운 영역에서의 아동의 언어능력을 측정하기 위하여 Kim(2018)에 포함된 음운인식 과제를 사용하였다. 과제는 첫 음절이 같은 소리로 시작되는 단어를 찾는 문항(우유-우산 아기 바지) 3문항과 끝 음절이 같은 소리로 끝나는 단어를 찾는 문항(주스-버스 주사 가시) 3문항, 첫 음소가 같은 소리로 시작되는 단어를 찾는 문항(나-너 가 소) 3문항, 총 9문항으로 구성되었다. 연습문항을 통해 아동이 과제를 이해하였다는 것을 확인한 후 본 과제를 실시하였다. 아동이 바르게 응답한 경우 1점, 틀린 반응을 보인 경우 0점으로 처리한 후 총합을 계산하였다. 아동이 얻을 수 있는 총 점수는 9점이었다.
의미 영역에서의 아동의 언어능력을 측정하기 위하여 한국어 수용 및 표현 어휘력 검사(Receptive and Expressive Vocabulary Test, REVT; Kim, Hong, Kim, Jang, & Lee, 2009) 중 수용 어휘력 검사를 실시하였다.
구문 영역에서의 아동의 언어능력을 측정하기 위하여 Kim (2018)에 포함된 문장 따라말하기 과제를 사용하였다. 과제는 모두 5낱말 길이로 단문 3문항, 접속 복문 3문항, 내포 복문 3문항, 총 9문항으로 검사자가 들려주는 문장을 듣고 그대로 반복하도록 하였다. 연습문항을 통해 아동이 과제를 이해하였다는 것을 확인한 후 본 과제를 실시하였다. 아동이 정확하게 따라 말한 경우 1점, 틀리게 따라 말한 경우 0점으로 처리한 후 총합을 계산하였다. 아동이 얻을 수 있는 총 점수는 9점이었다.
아동의 언어적 정보처리 용량을 측정하기 위해 Kim (2018)에 포함된 비단어 따라말하기 과제(Lee, Kim, & Yim, 2013)를 사용하였다. 비단어는 4음절(예: 토보가이), 5음절(예: 조매누버리), 6음절(예: 루지다마리노) 각 4개씩 총 12개로 검사자가 들려주는 단어를 듣고 그대로 따라 말하도록 하였다. 연습문항을 통해 아동이 과제를 이해하였다는 것을 확인한 후 본 과제를 실시하였다. 아동이 정확하게 따라 말한 경우 1점, 틀리게 따라 말한 경우 0점으로 처리한 후 총합을 계산하였다. 아동이 얻을 수 있는 총 점수는 12점이었다.
아동의 언어적 정보처리 속도를 측정하기 위해 Kim (2018)에 포함된 빠른 이름대기 과제를 사용하였다. 과제는 색깔 이름대기 과제, 사물 이름대기 과제, 숫자 이름대기 과제를 사용하였다. 색깔 이름대기 과제는 아동들에게 익숙한 색깔 6개(하양, 파랑, 초록, 보라, 빨강, 노랑)가, 사물 이름대기 과제는 아동들에게 익숙한 일음절 사물 6개(곰, 눈, 배, 코, 책, 달)가, 숫자 이름대기 과제는 숫자 6개(1, 3, 4, 6, 7, 8)가 무작위로 3번 반복되었으며, 각각 9× 2 배열로 제시되었다. 연구대상 아동들 모두 숫자를 읽을 수 있다는 것을 확인한 후 과제를 실시하였다. 이 세 가지 과제 각각에 대해, 아동에게 가능한 한 빠르고 정확하게 순차적으로 이름을 말하도록 지시하고, 시작부터 완료까지의 시간을 측정했다.
자료분석
전체 모집단이 서로 다른 분포를 가지는 집단들로 구성되어 있다고 가정하는 혼합모형 중 잠재프로파일분석을 실시하여 5-7세 아동의 언어능력을 가장 잘 설명할 수 있는 잠재집단을 선정하였다. 이 때 잠재프로파일분석의 시행은 Mplus 8.0 프로그램을 사용하였다. 잠재집단의 수가 결정된 이후에는 각 집단의 유형에 따라 언어능력 프로파일에 어떠한 차이가 있는지 살펴보고자 IBM SPSS Statistics 21.0 프로그램을 사용하여 다변량분석(MANOVA)을 하였다.
연구결과
측정변인의 기술통계치 및 상관
연구 대상자의 평균 연령은 74.67개월(SD = 8.80, range = 60-91)이었다. 연구의 주요 변인에 대한 기술통계는 Table 1에 제시하였다.

Descriptive statistics of major study variables (N=147)
이 중 4 SD 이상이 되는 이상치(outlier)는 분석에서 제외하였다(Kline, 2010; Stevens, 2002). 모든 변수값 중에서 하나가 이상치로 확인되었다. 이상치를 제거한 후, 해석을 용이하게 하기 위하여 모든 변수에 대하여 Z-점수를 산출하였다. 연구의 주요 변인인 언어 과제 간 상관표는 Table 2에 제시하였다.

Correlation of the measures used as group indicators
잠재집단의 수 선정
음운인식 과제, 수용어휘력 검사, 문장 따라말하기 과제, 비단어 따라말하기 과제, 빠른 이름대기 과제의 총 5가지 과제에서의 아동의 수행 양상에 따라 잠재집단을 분류하기 위하여 잠재프로파일 분석을 실시하였다. 5-7세 아동의 언어능력이 몇 개의 잠재집단으로 구분될 수 있는지 알아보기 위하여 집단의 수를 하나씩 늘려가며 단계적으로 잠재집단 모형을 확인하는 탐색적 방법을 사용하였고, 최적의 모형을 선정하기 위해 정보-기반 적합도 지수, Entropy 값, 우도비 검정 등을 확인하였다. 모형 적합도 지수의 종류는 다양하나, 본 연구에서는 선행연구에서 권고하고 있는 sample-size adjusted BIC (ADBIC)와 Entropy, LMR-LRT를 사용하였다(Lubke & Muthen, 2007; Magidson & Vermunt, 2004; Nylund, Asparouhov, & Muthén, 2007; Tofighi & Enders, 2008). 이와 함께 모형의 유용성 및 간결성, 해석 가능성 등을 전반적으로 검토하였다. 여러 가지 지표를 고려하여 2-5개의 잠재집단 모형의 결과를 Table 3에 제시하였다.

Fit statistics for the 2-, 3-, 4-, and 5-group solutions
모형의 적합성을 살펴보면, 잠재프로파일분석에서는 적합도 지수를 나타내는 ADBIC값이 작을수록 적합성이 좋음을 나타낸다(Nylund et al., 2007). 분석 결과, 집단의 수가 증가할수록 적합도 지수는 감소하였는데, 이는 더 많은 집단이 도출될수록 적합성이 향상됨을 의미한다. Entropy 값은 분류의 질을 나타내는 것으로, 모형이 개인을 특정 집단으로 얼마나 정확히 분류하는가에 대한 판단 기준이 된다. 0에서 1 사이의 값을 가지며 1에 가까울수록 집단 분류가 좋다고 평가한다(Muthen, 2006). 본 연구의 모든 집단의 Entropy 값을 살펴보면, 각 잠재집단은 .867-.917의 분포를 보이며, 적절히 분류된 것으로 판단할 수 있다. 다음으로 LMR-LRT는 잠재 집단 수를 늘려가면서 모형을 비교할 때, k개 모형을 k-1개 모형과 비교해 카이제곱의 차이를 검증하는 통계적 방법이다. 만약 검증에 대한 p값이 유의하면 k개 집단 모형이 k-1개 집단 모형보다 우수한 적합성을 지니는 것으로 판단한다. 본 연구에서는 2집단, 3집단, 4집단 모형이 .05 수준에서 유의한 것으로 나타났다.
이를 종합해 보면, 4-집단 모형에서, ADBIC는 3-집단 모형보다 적합하였고, LMR-LRT는 4-집단 모형이 3-집단 모형보다 우수한 적합성을 지닌다는 것을 보여주었다. Entropy는 .903으로 4-집단 모형을 가정하였을 때 집단 동질성이 만족스럽다는 것을 보여주었다(Table 3). 위의 통계적 기준들과 유의성, 해석가능성 등을 전반적으로 고려하여 4-집단 모형이 아동의 언어능력 유형을 가장 잘 보여주는 것으로 판단하였으며, 이후의 분석은 4-집단 모형을 기준으로 수행하였다.
최종적으로 선정된 4-집단 모형에 대하여 하위 지표에 따른 집단별 특성을 파악하여 집단을 명명하기 위한 잠재프로파일분석 결과는 Figure 1과 같다.

Four-group solution.
PA= Phonological Awareness Task; REVT-R=Korean Receptive and Expressive Vocabulary Test-Receptive (Kim et al., 2009); SR=Sentence Repetition Task; NWR=Non-Word Repetition Task; RAN=Rapid Automatic Naming Task.
잠재집단 1은 언어 과제의 5개 변인에서 모두 점수가 낮고, 특히 음운인식 과제와 빠른 이름대기 과제의 Z-점수가 -1.5 이하로 낮게 나타났다. 이 집단은 전체 아동의 12.3% (18명)이며, 다른 영역에 비해 빠른 이름대기 과제의 수행이 다른 집단보다 유의미하게 낮은 집단으로 확인되므로 ‘낮은 처리속도 집단’으로 명명하였다.
잠재집단 2는 언어 과제 5개 변인이 모두 낮은 점수를 보이고, 특히 문장 따라말하기 과제의 Z-점수가 -2 이하로 가장 낮게 나타났다. 이 집단은 전체 아동의 6.2% (9명)를 차지하며, 다른 영역에 비해 구문 영역 과제의 수행이 다른 집단보다 낮은 집단으로 확인되므로 ‘낮은 구문능력 집단’으로 명명하였다.
잠재집단 3은 언어과제 5개 변인 모두 평균에 가까운 수행을 나타냈다. 이 집단의 소속 확률은 65.8% (96명)로 가장 많은 아동들을 포함하며, 모든 점수에서 평균의 분포를 보이고 있으므로 ‘평균 집단’으로 명명하였다.
잠재집단 4는 언어과제 5개 모두 상대적으로 높은 수행을 보였다. 이 집단은 전체 아동의 15.7% (23명)로 모든 과제에서 상대적으로 높은 수행을 보이고 있으므로 ‘우수 집단’으로 명명하였다.
아동 언어능력의 잠재집단별 특성
잠재집단별로 각 과제 수행에 차이가 있는지 알아보기 위하여 다변량분석을 수행하였다. 독립변인은 4-수준의 집단 요인이었고, 종속변인은 5개 언어 과제였다. 통계는 Table 4에 제시되었다. 이와 함께 부분 에타 제곱(η2)을 구하여 각 결과의 효과 크기를 측정하였다. 일반적으로 η2값이 .14 이상이면 효과 크기가 크다고 할 수 있으므로(Gray & Kinnear, 2012), 모든 언어 과제에서 집단 간 평균 차이의 효과 크기가 .16-.65로 크게 나타났다. 그 중에서도 수용 어휘력 점수, 문장 따라말하기 과제 수행에서 가장 강한 관련성이 있었다. 이들 과제에서 효과크기는 각각 .65와 .62로 나타났다. 음운인식 과제, 빠른 이름대기 과제에서의 효과크기는 각각 .43과 .41로 비교적 강한 관련성이 있었다. 상대적으로 가장 약한 관련성은 비단어 따라말하기 과제로, .16의 효과크기를 나타냈다.

MANOVA results for group effect on the indicators
사후검정은 집단 평균들 사이에 짝비교를 수행하여 특정 잠재집단의 짝이 각 과제에서 유의미하게 다른지 보았다. 사후검정은 Bonferroni 검정을 사용했다. Figure 2에 통계적으로 유의미하지 않은 짝 비교가 동그라미로 표시되어 있다.
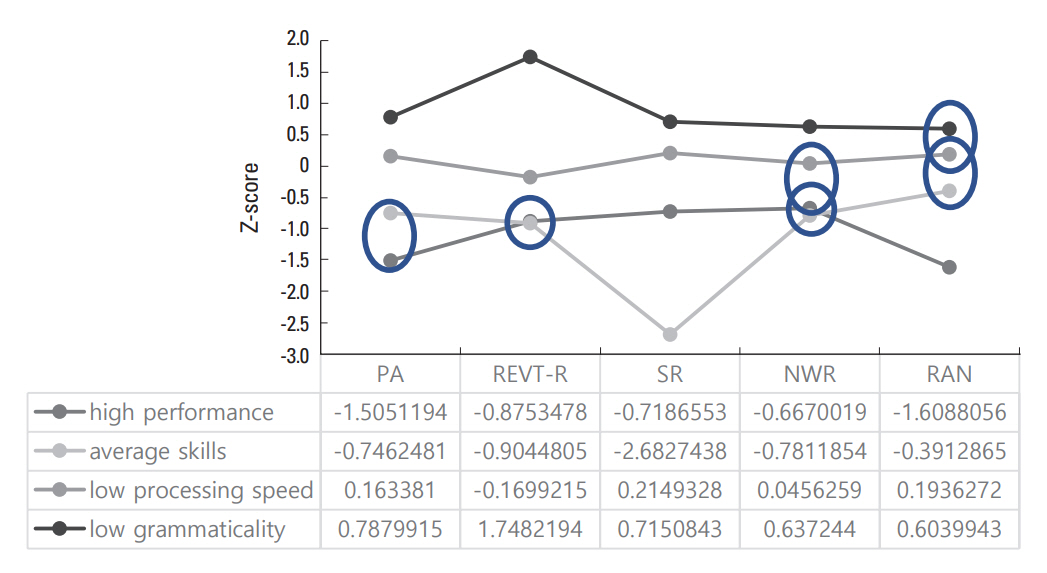
Four-group solution showing pairwise comparison results.
PA= Phonological Awareness Task; REVT-R=Korean Receptive and Expressive Vocabulary Test-Receptive (Kim et al., 2009); SR=Sentence Repetition Task; NWR=Non-Word Repetition Task; RAN=Rapid Automatic Naming Task.
‘낮은 처리속도 집단’과 ‘낮은 구문능력 집단’은 수용 어휘력 검사에서 ‘평균 집단’과 ‘우수 집단’보다 낮았다는 점에서 유사한 양상을 보였다. 그러나 ‘낮은 처리속도 집단’은 음운인식 과제와 빠른 이름대기 과제에서 다른 집단보다 낮은 수행을 보인 반면, ‘낮은 구문능력 집단’은 문장 따라말하기 과제에서 다른 집단보다 낮은 수행을 보였다.
논의 및 결론
본 연구의 주요 목적은 5-7세 한국어 사용 아동의 언어능력에 따른 잠재집단의 수와 그 특성을 알아보는 것이었다. 이를 위하여 구어 언어의 차원을 구성하는 음운, 의미, 구문 영역과 인지적 언어처리능력 중 처리용량과 처리속도 영역에서 아동의 언어능력을 살펴보았다. 각각의 영역은 음운인식 과제, 수용 어휘력 검사, 문장 따라 말하기 과제, 비단어 따라말하기 과제, 빠른 이름대기 과제로 측정했다.
잠재프로파일분석 결과, 4-집단 모형이 최적의 모형으로 선택되었다. 먼저 모든 과제에서 상대적으로 우수한 수행을 보였던 “우수 집단(15.7%)”, 모든 과제에서 평균 수준의 수행을 보였던 “평균 집단(65.8%)”, 그리고 두 개의 하위 집단으로 나뉘었다. 두 개의 하위 집단은 모든 언어 과제에서 점수가 낮았으나, 상대적으로 빠른 이름대기 과제의 수행이 낮았던 “낮은 처리속도 집단(12.3%)”과 모든 언어 과제에서 점수가 낮았지만 특히 문장 따라말하기 과제의 수행이 낮았던 “낮은 구문능력 집단(6.2%)”이었다.
본 연구결과, 5-7세 아동 언어능력의 잠재집단은 크게 아동의 수행 수준에 따라 나누어지는 것처럼 보였다. 이러한 연구결과는 아동 언어능력의 연속성을 보여주었던 기존의 연구들과 함께하는 결과를 보여준다(Dollaghan, 2004; Tomblin & Zhang, 1999). 본 연구에서 아동 언어능력의 잠재집단이 수행 수준에 따라 나뉘어진 이유는 일반 아동을 대상으로 언어능력의 차원성을 살펴보았기 때문일 수 있다. 연구자들은 일반 아동의 경우, 하나의 언어 영역에서의 수행이 우수한 아동은 다른 영역에서도 높은 수행을 보이는 경향이 있다고 해석했다(Tomblin & Zhang, 2006). 아동 언어능력의 하위집단을 살펴본 선행연구들도 일반 아동을 대상으로 한 연구들의 경우에는 아동 언어능력에 있어서 수행의 연속성을 보여준 반면(Dollaghan, 2004; Tomblin & Zhang, 1999), 언어장애 아동을 대상으로 한 연구들의 경우에는 하위집단의 존재를 보여주었다(Bishop et al., 1995; Conti-Ramsden et al., 1997; Rapin & Allen, 1983). 본 연구에서도 모든 언어 과제에서 상대적으로 낮은 수행을 보였던 아동들의 경우 서로 다른 프로파일을 가진 두 개의 잠재집단으로 나뉘어져서 이러한 경향을 확인할 수 있었다.
즉, 전체 언어 과제에서 전반적으로 낮은 수행을 보인 하위 집단의 경우, 단순히 하나의 집단이 아닌 처리속도에서 상대적으로 낮은 수행을 보이는 잠재집단과 구문능력에서 상대적으로 낮은 수행을 보이는 잠재집단으로 나뉘었다. 먼저, 본 연구는 빠른 이름대기 과제에서 다른 집단보다 낮은 수행을 보이는 ‘낮은 처리속도 집단’ 을 판별해 내었다. 본 연구의 ‘낮은 처리속도 집단’은 수용 어휘력 검사를 포함한 다른 언어 과제에서도 상대적으로 낮은 수행을 보였고, 음운인식 과제와 빠른 이름대기 과제의 Z-점수가 -1.5 이하의 낮은 수행을 보였다. 특히 빠른 이름대기 과제에서 다른 집단들보다 유의하게 낮은 수행을 보였기 때문에 ‘낮은 처리속도 집단’이라고 명명했다. 이는 일부 아동의 경우 낮은 처리속도로 말미암아 상대적으로 낮은 언어능력을 보일 가능성을 보여주었다. 5-7세 스페인어-영어 이중언어 아동을 대상으로 아동 언어능력의 차원성을 알아본 Kapantzoglou 등(2015)의 연구에서도 낮은 구문능력 집단과 인지적 언어처리능력에 어려움이 있는 잠재집단을 확인했다. 그러나 Kapantzoglou 등(2015)의 연구에서는 낮은 구문능력 집단과 함께 낮은 음운기억용량 집단이 구별되었던 것과 달리, 본 연구에서는 ‘낮은 구문능력 집단’과 함께 ‘낮은 처리속도 집단’이 확인되었다. 이에 대하여 다음과 같은 해석이 가능하다. 본 연구의 ‘낮은 처리속도 집단’의 경우 처리속도 과제뿐만 아니라 음운인식 과제에서도 Z-점수가 -1.5 이하의 상대적으로 낮은 수행을 보였음을 상기할 때, 이 집단이 음운정보의 처리속도뿐만 아니라 음운인식능력을 포함하는 음운처리능력(Wagner & Torgesen, 1987)에서 상대적으로 어려움을 보이는 집단일 수 있다. ‘낮은 처리속도 집단’의 존재는 언어평가에서 평균 혹은 평균 이하의 수행을 보이는 아동 중 일부는 낮은 음운처리능력을 보인다는 것을 시사한다. 많은 선행연구에서 이러한 낮은 음운처리능력을 가진 프로파일의 존재가 보고되었다. 이들은 아동의 음운처리능력이 의미 및 구문능력과는 별개로 아동 언어능력의 차원을 구성한다고 보고했다(Anthony et al., 2014; Foorman et al., 2015; Tomblin et al., 2004). 그러나 낮은 언어 수행을 보이는 모든 아동이 낮은 음운처리능력을 보이는 것은 아니다(Miller et al., 2001). 이에 대하여 Leonard 등(2002)은 음운처리에 기인한 언어문제(예, 난독증)와 음운처리에 기인하지 않은 언어 문제(예, 단순언어장애)를 구분하였다. 본 연구에서는 처리속도 과제와 음운인식 과제가 낮은 음운처리능력을 특징으로 하는 언어능력 집단을 식별하는데 유용하다는 것을 보여주었다. 아동의 음운 처리능력이 향후 문해능력의 강력한 예측 인자이고(Snow, Burns, & Griffin, 1998), 구어와 문어를 잇는 중요한 연결고리라는 점을 고려할 때 이 집단에 대한 보다 세심한 관심이 필요할 것이다.
다음으로, 본 연구는 문장 따라말하기 과제에서 다른 집단보다 낮은 수행을 보이는 ‘낮은 구문능력 집단’을 판별해 내었다. 비록 방법론과 연구대상에 있어서 차이가 있지만 선행연구에서도 낮은 구문능력을 가진 집단의 존재를 보여주었다(Bishop, 1994; Conti-Ramsden et al., 1997; Kapantzoglou et al., 2015). 각각의 연구들이 서로 다른 지표를 사용함에 따라 직접적으로 집단을 비교할 수는 없으나, 모든 연구에서 의미 영역과 구문 영역의 측정이 포함되었다. 5-7세 스페인어-영어 이중언어 아동을 대상으로 언어능력 프로파일을 살펴본 Kapantzoglou 등(2015)의 연구에서도 낮은 구문능력 집단이 확인되었고, 언어장애를 가진 7-10세 쌍둥이 90명을 대상으로 한 Bishop (1994)의 연구에서 또한 문장 따라말하기 과제에서만 제한을 보이는 집단을 판별해 내었다. 본 연구에서의 ‘낮은 구문능력 집단’은 구문 영역에서는 낮은 점수(즉 평균으로부터 -2.5 SD 이하)를 보였으나, 의미 영역에서는 Z-점수가 -1 이내로 나타났다. Conti-Ramsden 등(1997)에서도 낮은 구문능력을 보이지만 의미 영역의 능력은 보존된 집단이 존재했고, Bishop (1994)의 연구에서도 문장 따라말하기 과제에서는 제한을 보이지만 낱말 찾기 과제에서는 문제가 없는 집단이 존재했다. 그러나 Bishop (1994)과 Conti-Ramsden 등(1997)에서 의미와 구문 영역 모두에서 낮은 수행을 보인 집단이 존재한 반면, 본 연구에서는 Kapantzoglou 등(2015)의 연구와 마찬가지로 의미와 구문 영역 모두에서 낮은 수행을 보인 집단이 존재하지 않았다. 이러한 차이는 Bishop (1994)과 Conti-Ramsden 등(1997)의 연구는 언어장애 아동을 대상으로 한 반면 Kapantzoglou 등(2015)과 본 연구는 일반 아동을 대상으로 하였기 때문인 것으로 보여진다. 또한 본 연구에서의 낮은 구문능력 집단 또한 언어발달이 정상범주 내의 아동들로 추후 언어발달장애 아동을 포함한 후속연구가 필요하다.
‘낮은 구문능력 집단’의 존재는 아동 발화의 구문적 지표가 아동 언어능력의 신뢰로운 지표라는 선행연구들의 주장과 일치한다(Archibald & Joanisse, 2009; Stokes et al., 2006). 본 연구에서 잠재 집단들 사이에 각 과제 수행에서의 차이의 효과크기를 살펴본 결과, 문장 따라말하기 과제에서 가장 강한 관련성이 나타났다는 사실이 이러한 주장을 뒷받침한다. ‘낮은 구문능력 집단’의 존재는 언어장애의 원인 측면에서도 아동 언어장애의 주요한 원인이 어휘 학습에서의 어려움이 아니라, 언어의 문법 규칙 습득에서의 어려움이라는 주장을 뒷받침한다(Rice, Cleave, & Oetting, 2000; van der Lely, 2005).
다만 본 연구에서는 아동의 구문능력을 측정하기 위하여 문장 따라말하기 과제를 실시했으나(Foorman et al., 2005; LARRC, 2017; LARRC et al., 2018; Semel et al., 1980), 아동이 문장 따라말하기 과제를 수행하기 위해서는 다양한 언어적 측면이 유기적으로 얽혀 작용하는 것처럼 보인다. 일부 연구자들은 문장 따라말하기 과제가 어휘 지식, 작업기억용량 등과 같은 각각의 언어능력을 평가한다기 보다는 하나의 통합된 언어구조의 처리능력을 측정하는 것이라고 설명하였다(Klem et al., 2015). 아동이 실제 언어적인 정보를 처리하는 상황에서는 단순히 단어들의 집합이 아닌 전체 문장 수준에서 좀 더 상위 수준의 문맥을 이용할 수 있는 능력이 요구된다는 점(Kroll & Bialystok, 2013)과 최근 언어장애의 연구 분야와 임상 현장에서 단어 수준의 산출이 아닌 문장 수준의 처리 능력에 집중하고 있는 경향을 고려할 때, 향후 문장 따라말하기 과제의 처리 기제에 대한 보다 심도 있는 연구가 이루어져야 할 것이다.
본 연구에서는 하위집단에서 서로 다른 프로파일을 가진 잠재집단의 존재를 확인하였다. 이는 “흔히 성공의 이유를 하나의 요소에서 찾으려 하지만 실제로 무언가 성공을 위해서는 수많은 실패 원인을 피할 수 있어야 한다(Diamond, 1997, p. 157)”는 안나 카레니나의 법칙이 아동의 언어발달에도 적용이 될 수 있음을 시사한다. 즉, 아동의 언어발달을 위해서 필요한 여러 가지 언어 영역들(음운, 의미, 구문 등)과 여러 가지 인지적 자원들(처리용량, 처리속도 등) 중에 한가지만이라도 부족하면 언어발달에 어려움이 있을 수 있다는 것이다. 이는 또한 다른 한 편으로는 비록 언어발달에 어려움을 가진 아동들이라도 각각의 언어 영역에서 강점과 약점을 가진 프로파일을 가지고 있을 수 있다는 것을 의미한다.
본 연구의 제한점으로, 우선 대상자 선정 측면에서 사례 수가 적어 더 많은 수의 잠재집단이 분류될 가능성을 제한했거나 잠재집단 분류가 왜곡되었을 수 있다. 비록 본 연구에서는 언어장애가 없다고 보고된 아동을 대상으로 하여 연구를 진행하였으나, 하위집단에서의 서로 다른 잠재프로파일의 존재를 확인하였다. 이는 언어장애 아동 집단에서의 하위집단의 존재를 예측하게 한다. 또한 본 연구에서는 5-7세 아동 집단을 대상으로 하여 다소 큰 연령 범위가 연구결과에 영향을 미쳤을 것으로 보인다. 후속연구에서는 이러한 점을 보완하여 다양한 집단을 대상으로 연구가 이루어질 필요가 있다. 검사 과제 측면에서는 본 연구가 구어 언어구조를 이루는 음운, 의미, 구문 영역을 살펴보기 위하여 음운인식 과제, 수용 어휘력 검사, 문법 따라말하기 과제를, 인지적 언어처리 영역의 처리 용량과 처리속도를 살펴보기 위하여 비단어 따라말하기 과제, 빠른 이름대기 과제를 사용하였다. 그러나 아동의 전반적인 언어능력을 되도록 빠짐없이 측정하기 위해서는 좀 더 다양한 검사들을 사용한 후속연구가 필요할 것이다.