구어처리 과제를 이용한 학령기 다문화가정 아동의 언어장애 예측요인 연구
Predictors of Language Disorders in School-Aged Children from Multi-Cultural Families: Vocabulary Knowledge-Based Tasks and Language Processing Tasks
Article information

Abstract
배경 및 목적
본 연구에서는 다문화가정 아동 언어평가에 널리 사용되고 있지만 언어지식과 경험 의존적인 표준화 검사를 포함한 어휘지식 평가와 다문화가정 아동에게 덜 편향적(biased)인 것으로 알려진 구어처리 과제의 언어장애 예측 여부와 설명력에 대해 알아보고자 하였다.
방법
생활연령을 6개월 이내로 일치시킨 6-11세 초등학교 다문화가정 정상 언어아동(15명)과 다문화가정 언어장애아동(15명), 일반가정 정상언어 아동(15명) 등 총 세 집단 45명을 대상으로 어휘검사와 비단어따라말하기 과제(NRT)와 문장폭기억 과제(CLPT)를 실시하였다. 월령과 지능을 제어변인으로 하고 정상언어 집단과 언어장애 집단의 이분변인인 종속변인을 포함하여 변인들 간의 관계를 알아보기 위해 편상관 분석을 실시하고, 언어수준별 집단(정상언어집단, 언어장애집단)을 종속변인으로 하고 각 과제 수행을 독립변인으로 하여 이항로지스틱 회귀분석을 실시하였다.
결과
구어처리 변인이 단일 투입되었을 때 집단 구분에 영향을 주는 것으로 나타났다. 구어처리 과제 변인을 입력방식으로 모두 투입한 로지스틱 회귀분석에서는 월령과 CLPT 낱말회상 점수 변인이 유의수준 .05에서 언어장애 여부 결정에 유의하게 영향을 미치는 것으로 분석되었다. 단계선택 방법으로 도출한 회귀방정식에는 월령과 CLPT 낱말회상 점수, NRT 음절 점수가 유의한 변인으로 모형에 포함되었으며, 전체 모형의 집단 분류 정확률은 88.4%로 높았다.
논의 및 결론
본 연구 결과는 학령기 다문화가정 언어장애 아동과 다문화가정 및 일반가정의 정상언어 아동을 예측하는 데 비단어따라말하기와 문장폭기억 과제등의 구어처리 과제가 유용함을 시사한다.
Trans Abstract
Objectives
The purpose of this study was to evaluate the diagnostic accuracy of ‘vocabulary knowledge-based’ measures, including a standardized vocabulary test, and ‘language processing’ measures administered to school-aged children from multicultural families.
Methods
Three groups of school-aged children (typically developing children from non-multicultural families, typically developing children from multicultural families, and multicultural children with a language delay), aged 6-11, were recruited and have went through three knowledge-based tests (Receptive & Expressive Vocabulary Test expressive/receptive tests and culture-related vocabulary expression test), and two processing-dependent measures (nonword repetition [NRT], competing language processing task [CLPT]). All three groups were matched in terms of family income, and 1 to 1 matched by age (in months) within ±6 months.
Results
Logistic regression analysis revealed that there was compara-ble diagnostic accuracy for both knowledge-based vocabulary measures and processing dependent measures. When all measures were put into regression analysis at once, however, processing dependent measures, in particular the CLPT recall measures, were the most predicting factors.
Conclusion
It is significant that processing measures, which are less time-consuming and more independent to language experience or knowledge, have significant predictive power on identifying language impairments in school-aged multicultural children. Further study is needed regarding processing measure to assure the predictive value with populations from various socioeconomic status backgrounds and other family factors in order to be put it into practice as an assistive or primary diagnostic procedure.
표준화검사가 다문화가정 아동들에게 표집(sampling)상의 문제나 언어경험과 지식에 의존한다는 이유로 불리하다는 인식이 확산되면서, 그 대안으로 공식검사에 비해 언어지식이나 경험에 덜 의존하는 처리과정 중심평가를 다문화 ·다언어가정 아동에게 적용하는 연구가 활발히 진행되어 왔다(Laing & Kamhi, 2003). 이러한 처리과정 관련 과제는 다양한 기억 과제(digit span, 작업기억, 비단어따라말하기), 지각 과제(빠르게 제시되는 음의 변별, 빠른 일련의 소리들의 순서매기기), 또는 경쟁자극 과제(Campbell, Dollaghan, Needleman, & Janosky, 1997) 등을 포함하는데 이 중에서도 다문화 다언어가정 아동과 일반아동 간 집단 차이 연구나 진단정확도 연구에서 가장 활발하게 연구되고 있는 과제는 비단어따라말하기(nonword repetition, NRT)이다.
비단어따라말하기는 공식검사에서의 언어능력의 영향(Ellis Weismer et al., 2000), 또 성별 차이나 방언의 영향(Oetting et al., 2008), 또 일반아동들 내에서 사회경제적 지위의 영향을 받지 않은 것으로 나타났다(Chiat & Roy, 2007). 특히 대규모 집단을 이용한 Ellis Weismer 등(2000)에서 다양한 인종 배경을 가진 아동들이 표준화검사 점수에서는 유의하게 낮았으나 비단어반복 과제에서는 주류 집단 아동과 차이를 보이지 않았으며, 언어장애 아동은 또래 일반아동에 비해 비단어반복 과제에서 어려움을 보였음을 보고하였다.
영어사용 일반아동과 SLI 아동을 대상으로 비단어따라말하기 과제를 사용한 23개 연구의 메타 분석(Graf Estes, Evans, & Else-Quest, 2007)에서도 짧은 음절에서는 연령 일치 비교집단 아동에 비해서 차이가 적지만 긴 음절에서는 더 큰 집단 차이를 보였으며, Kan과 Windsor (2010)의 메타분석연구에서는 언어장애 아동이 또래 일반아동에 비해 유의미하게 낮은 비단어따라말하기 수행을 보였고 음절이 길어질수록 집단 간 차이는 증가하였다. Guiberson 과 Rodriguez (2013)에서는 3-5세 스페인어 사용 일반아동과 언어장애 아동의 비단어따라말하기 기술을 비교한 결과 일반아동에 비해 유의미하게 낮은 수행을 보여서 비단어따라말하기 과제가 3-5세 스페인어 사용 일반아동과 언어장애 아동을 성공적으로 변별할 수 있음을 보여주었다. Paradis, Emmerzael과 Duncan (2010)의 연구에서는 다양한 다양한 모국어 배경의 순차적 영어학습자 178명을 대상으로 모국어(L1) 발달에 대한 부모 질문지와 비단어반복 과제, 어휘검사, 이야기 평가 등의 영어평가도구가 일반아동과 언어장애 아동을 구별할 수 있는지 살펴보았다. 그 결과 영어학습자 아동 중 일반아동은 어휘검사를 제외한 모든 검사에서 언어장애 아동보다 높은 점수를 얻었으며, 지식 기반의 어휘검사에서는 영어학습 아동 모두가 장애 여부와는 관계없이 어려움을 보였다.
우리나라에서도 비단어따라말하기 연구는 집단 간 차이 연구에서 이중언어 아동과 일반아동 간에(Lee, 2010), 또 다문화가정 언어장애 아동과 정상언어집단 간에 차이가 있는 것으로 보고되었다(Oh & Kim, 2014).
무의미낱말반복 과제가 과제를 구성함에 있어 특정 언어의 음운론적 영향을 받을 수 있고 이에 따라 다양한 언어문화적 배경을 지닌 아동들에게 실시했을 때 아동의 언어적 배경에 따라 난이도가 달라질 수 있다는 점을 고려하여 음운론의 영향을 덜 받는 문장수준의 처리과제가 다문화가정 아동의 진단에 권고되기도 하였다(Laing & Kamhi, 2003).
Gaulin과 Campbell (1994)은 기존의 문장외우기 과제(the Daneman and Carpenter sentence span task)를 수정하여 문장폭기억 과제(competing language processing task, CLPT)를 만들었는데 이는 아동에게 짧은 문장 리스트를 들려주고 각 문장의 마지막 낱말을 기억하는 동시에 문장 내용의 정오를 판단하게 하는 과제이다. 문장 리스트는 각 단계별로 1개에서 6개 문항으로 구성되며 매 문장마다 정오판단 질문을 하고 문장 리스트의 마지막에 기억하고 있던 문장의 마지막 낱말들을 모두 말하게 하였다. 연구결과, 일반아동은 연령 증가에 따라 정확하게 회상한 낱말 비율이 유의하게 증가하였으며, CLPT에서의 목표낱말 회상과 어휘력검사(PPVT) 점수의 상관관계가 유의미하여 구어 작업기억과 수용어휘 능력이 상호 관련된 기술임을 밝혔다.
선행연구들에서 언어장애 아동은 일반 또래 아동에 비해 유의하게 적은 낱말을 회상하였다. Ellis Weismer와 Thordardottir (2002)는 언어장애 아동의 CLPT 수행과 무의미낱말반복 과제와 비교하였다. 전통적으로 CLPT가 단기기억 용량과 구어 정보 처리를 동시에 측정한다고 보는 반면에 무의미낱말반복은 주로 단기기억 용량만을 측정한다고 여겨져 왔다(Gathercole & Alloway, 2006). Ellis Weismer와 Thordardottir (2002)는 무의미낱말반복에서의 수행이 SLI 아동의 표준화언어검사에서의 수행 부분을 설명하고 CLPT 의 목표낱말 회상은 SLI 아동의 언어능력 변이성의 더 많은 부분을 설명할 수 있다고 보았다.
Campbell 등(1997)에서는 ‘지식의존 과제’(공식검사의 어휘 과제)와 ‘처리과정 과제’(NRT와 CLPT)를 학령기 다언어다문화(culturally linguistically diverse, CLD) 아동(11-14세)에게 실시한 결과, 다언어다문화 아동은 지식의존 과제, 즉 공식검사 점수에서 일반아동들에 비해 낮은 수행을 보였으나 처리과정 과제(NRT, CLPT)에서는 일반아동 집단과 차이를 보이지 않았다. 이는 기존의 공식검사, 즉 지식의존 과제에 비하여 비단어따라말하기(NRT)와 문장폭기억 과제(CLPT)로 구성된 처리과정 중심 평가가 다언어다문화 아동에 대해 편견이 적은 과제임을 시사한다.
Rodekohr와 Haynes (2001)는 NRT와 CLPT의 처리과정 평가와 지식의존 과제로 볼 수 있는 공식언어검사(TOLD-I-2)를 7세 아프리카계 아동과 비아프리카계 아동 집단에 실시하였다. 그 결과, 표준화 언어검사와는 달리 CLPT가 아프리카계 영어(African-Amer-ican English, AAE) 사용자를 편견 없이 평가할 수 있는 과제이고 일반 아프리카계 영어 사용 일반아동과 SLI 아동을 성공적으로 구분하였음을 보여주었다. 이 연구에서는 아프리카계 아동과 비아프리카계 아동 집단을 각각 전형적인 발달을 보이는 아동과 언어장애를 보이는 아동의 두 하위 집단으로 나누어 총 4개의 집단을 비교하였다. 그 결과 인종이나 방언 사용에 관계없이 처리과정 과제가 일반아동과 언어장애 아동을 효과적으로 변별할 수 있었다. 지식기반 과제에서 아프리카계 아동은 비아프리카계 아동에 비해 낮은 수행을 보였으나 처리과정 중심평가에서는 비아프리카계 아동들과 비슷한 수행을 보였다. 또한 이 결과는 또래 아동과 비슷한 처리능력을 가진 아프리카계 아동들이 규준참조 평가에서는 결함이 있는 것으로 평가될 수 있음을 시사하였다.
이렇게 상대적으로 언어경험에 대한 편견이 적은 진단도구로서의 잠재성이 확인되면서(Campbell et al., 1997) 비단어따라말하기(NRT)와 문장폭기억 과제(CLPT)는 집단 간 차이 연구뿐만 아니라 언어장애 여부를 변별해 주는 진단정확도 연구에 사용되기 시작하였다(Chiat & Roy, 2007; Girbau & Schwartz, 2007). 특히 NRT 와 CLPT는 다양한 공식검사, 부모설문 및 가족력(Restropo, 1998), 새 형태소 학습하기(Jacobson & Schwartz, 2005)와 같은 다양한 측정치들과 함께 언어문화적 배경이 다양한 아동 집단 내에서 언어장애 아동과 정상발달 아동을 구분하는 데 사용될 수 있는지 변별 진단 가능성 연구가 활발히 진행되었다(Dispaldro, Leonard, & Deevy, 2013; Guiberson & Rodriguez, 2013).
가장 먼저 Dollaghan과 Campbell (1998)은 언어장애 아동을 변별함에 있어 비단어따라말하기 과제(NRT)가 표준화검사보다 더 높은 정확도가 있음을 보여주었고, Leonard 등(2007)도 SLI 아동의 용량 제한을 연구하였는데 이때 사용한 작업기억 과제가 CLPT 와 문법적 판단을 추가한 수정된 듣기폭 과제(listening span task)였다.
Girbau와 Schwartz (2008)는 약 9세 학령기 영어-스페인어 SLI 아동과 정상언어발달 아동 각 11명을 3-5음절의 비단어따라말하기 과제로 진단정확도를 살펴본 결과, 11명의 정상언어발달 아동 중 10명이, 11명의 언어장애 아동 중 9명이 정확히 분류되어 높은 진단정확도를 나타내 이 집단 아동들의 유의미한 언어장애판별 과제임을 알 수 있었다. Guiberson과 Rodriguez (2013)에서는 3-5세 스페인어 사용 일반아동과 언어장애 아동의 비단어따라말하기 기술을 비교한 결과 일반아동에 비해 유의미하게 낮은 수행을 보여서 비단어따라말하기 과제가 3-5세 스페인어 사용 일반아동과 언어장애 아동을 성공적으로 변별할 수 있음을 보여주었다.
영어-스페인어 이중언어 아동의 언어평가 연구들을 메타분석한 Dollaghan과 Horner (2011)에서는 비단어따라말하기, 낱말정의하기, T-unit당 오류율, 낱말 정의하기, 스페인어 형태구문검사, 과거시제, 발화길이, 부모보고, 가족력 등의 측정치들이 모두 우도비(likelihood ratio)가 양호한 편이어서 언어결함을 판별하는 후보군들로 생각할 수 있다고 보았다. 하지만 이 중 어떤 변인도 한 가지 측정치가 정상발달 아동과 언어결함 아동을 판별하는 월등한 방법으로 평가되지 않았고, 이 측정치들은 언어결함 여부를 판단하기 위해선 다른 부가적인 정보로 보완되어야 한다고 보고하였다.
Kohnert, Windsor와 Yim (2006)의 연구에서도 CLPT와 NRT 과제에서 영어 단일언어 아동과 영어 단일언어 사용 언어장애 아동과 영어-스페인어 이중언어 아동의 수행을 살펴본 결과, 집단 간 차이 비교에서는 단일언어 사용 정상발달 아동, 이중언어 아동, 단일언어 언어장애 아동 순으로 높은 수행을 보여 통계적으로 유의한 차이를 보였으나, 우도비 분석 결과 경쟁언어처리 과제(CLPT)와 비단어따라말하기(NRT)가 정상언어발달 이중언어 아동과 단일언어 사용 언어장애 아동을 구분할 수 있는 충분한 진단력을 가지고 있다고 보기는 어렵고, 다만 NRT에서 93% 이상의 수행력을 보이는 경우 언어장애 진단에서 제외될 수 있다고 결론지었다.
이러한 연구들은 처리과정 중심평가가 일반적인 처리능력을 가졌지만 언어지식이나 경험이 부족한 다문화가정 아동과 언어장애 아동을 변별진단하는 데에 잠재력 있는 도구라는 것을 보여준다. 문화적 배경이 다른 아동들이 증가하고 있는 우리 나라에서도 표준화검사를 보완해 줄 수 있는 다양한 자발화 측정치, 가정환경 요인들과 함께 NRT나 CLPT와 같은 구어처리 과제에 대한 관심이 높아지고 있으며, 진단현장에서 실제로 사용되고 있다(Korean Institute for Healthy Family, 2018). 최근에는 기존 표준화 언어검사와 구어처리 과제까지 포함한 폭넓은 과제에서 다문화가정 언어장애 아동과 정상언어 아동(일반가정/다문화가정)을 비교하는 연구가 진행되기도 하였다. Oh와 Kim (2014)에서는 어휘지식 과제(RE-VT점수/문화어휘점수)와 구어처리 과제(NRT음절 점수/CLPT 낱말회상)에서 집단 간 유의한 차이가 있었고, 다문화가정 언어장애 아동의 모든 어휘지식검사와 CLPT 낱말회상 점수에서 두 정상언어집단(일반가정/다문화가정)과 유의한 수행 차이를 보였다. 그러나 근거기반 평가에서는 진단평가나 과제의 진단정확도를 검증하기 위해서는 실제 신뢰할만한 참조기준(reference standard)에 의해 나누어진 집단을 그 과제가 얼마나 정확히 분류할 수 있는지를 검증해 보아야 한다(Dollaghan & Horner, 2011; Sackett, Straus, Richardson, Rosenberg, & Haynes, 2000). 그러므로 국내에서도 구어처리 과제들이 다문화가정 아동의 진단에 사용되기 위해서는 집단 간 차이 연구에서 더 나아가 실제 다문화가정의 민감도(sensitivity)와 특이도(specificity)를 밝히는, 임상적 유용성에 대한 연구가 필요한 시점이다.
그러므로 본 연구에서는 다문화가정 언어장애 아동들과 소득과 연령을 일치시킨 두 정상아동 집단(다문화가정/일반가정)을 대상으로, 표준화 어휘검사를 포함한 어휘지식 과제와 그에 비해 덜 편향적이라고 평가되는 구어처리 과제(비단어따라말하기, 문장폭기억 과제)에서의 수행이 학령기 다문화가정 아동의 언어장애 여부를 예측할 수 있는지 살펴보고자 한다.
본 연구의 연구문제는 어휘지식과 구어처리 과제 수행력이 다문화가정 아동의 언어장애 확률에 영향을 주는지, 그리고 각각의 과제에서 더 많은 영향을 주는 변인이 무엇인지를 알아보는 것이다.
연구방법
연구대상
본 연구의 대상은 서울·인천·경기지역에 거주하는 6-11세 학령기 아동으로, 소득 수준과 생활연령(±6개월)을 일치시킨 세 집단, 즉 다문화가정 정상언어 집단(15명), 다문화가정 언어장애 집단(15명), 일반가정 정상언어 집단(15명)으로 총 45명이었다.
두 정상언어 아동 집단(다문화가정과 일반가정)은 (1) 부모나 교사에 의해 언어, 다른 감각 및 정서·행동상의 문제가 없다고 보고된 아동이며, (2) 한국 웩슬러 아동지능검사-III (Korean Wechsler Intelligence Scale for Children-III, K-WISC-III: Kwak, Park, & Kim, 2001)를 실시하였을 때 동작성 지능지수가 −1 표준편차(85) 이상이고, (3) 학령기아동언어검사(Language Scale for School-aged Children, LSSC; Lee, Heo, & Jang, 2015)에서 총점이 −1.25 표준편차 이상으로 하여, (4) 부모나 교사가 아동의 언어능력이 정상이라고 보고하고, 언어치료를 받았던 경험이 없는 아동으로 하였다. 다문화가정/일반가정 아동은 위의 정상 아동 기준 외에 한국인 아버지와 결혼이민자 어머니 사이에서 태어난 아동으로 한국에서 태어나고 자랐으며 제1언어가 한국어인 아동으로 하였다. 한국어 외의 언어를 주 언어로 사용하거나 2년 이상 해외 거주 경험이 있는 아동은 대상에서 제외하였다. 세 집단의 어머니 출신국 분포는 Table 1과 같다.

The distribution of age & gender of the children and the mother's country
다문화가정 언어장애 아동을 선정하는 기준은 Girbau와 Schwartz (2008), Roseberry와 Connell (1991)의 연구를 참고하여, (1) 지능은 정상 범주이면서, (2) 부모나 교사에 의해서 언어문제가 있다고 보고되며, (3) 언어영역 전반에 대한 하위평가로 이루어진 학령기아동언어검사(LSSC)에서 총점이 −1.25 표준편차 미만이며, (4) 과거에 전문적인 언어치료기관에서 언어치료를 받은 경험이 있고 현재도 받고 있거나 6개월 이내의 언어진단에서 1급 언어재활사에 의해 언어치료 서비스를 받을 필요성이 있다고 진단된 아동으로 하였다.
선행연구(Kim, 2011)에서 아동의 언어 수행에 영향을 줄 수 있는 요인으로 언급된 사회경제적 지위, 그중에서도 소득 수준을 다문화가정 아동 집단의 소득에 일치하도록 통제하였다. 최저생계비의 120%까지(4인 기준 185만 원)의 차상위계층 아동 비율은 비다문화 일반아동 집단 80% (12명), 다문화가정 일반아동 집단 73.3% (11명), 다문화가정 언어장애 집단이 80% (12명)이었고, 나머지 20%-26.7% 정도가 중산층 가정 아동이었다.
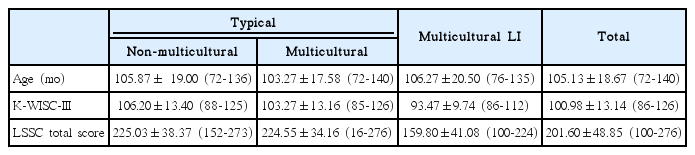
세 집단 아동들의 월령, 동작성 지능지수, 그리고 LSSC 총점에 대한 기술통계는 Table 2에 제시하였다.
Characteristics of participants
세 집단의 동질성 검정을 위해 실시한 일원분산분석(one-way ANOVA) 결과, 세 집단 간 아동의 월령 (F(2, 42) =.110, p>.05)에는 유의한 차이가 없었지만 LSSC 총점 (F(2, 39) =13.928, p < .001)과 지능 (F(2, 42) = 4.470, p < .05)에서는 유의한 차이를 보였다. LSSC 총점은 다문화가정 언어장애 집단과 다문화가정 정상언어 집단, 다문화 언어장애 아동과 일반가정 정상언어 집단 간의 차이가 유의하였고, 지능은 일반가정 아동과 다문화가정 언어장애 아동 간에서만 유의한 차이가 있었다. 두 정상언어 집단(일반가정과 다문화가정) 간에는 LSSC 총점과 지능에서 모두 유의한 차이가 없었다.
연구절차 및 분석
자료수집 도구
어휘지식 과제
언어장애 아동과 일반아동을 변별할 수 있는 과제가 무엇인지 알아보기 위하여 2개의 어휘지식 과제를 실시하였다. 어휘지식 과제로는 먼저 수용 ·표현어휘검사(Receptive & Expressive Vocabulary Test, REVT; Kim, Hong, Kim, Jang, & Lee, 2009)를 그대로 사용하였고, 이에 더해 한국 문화를 더욱더 반영하는 한국문화 기초어휘(National Institute of the Korean Language, 2001) 중 연구자가 18개를 선별하여 대면이름대기 과제로 구성한 한국 문화어휘 표현검사(Oh & Kim, 2014)를 실시하였다(Appendix 1).
구어처리 과제
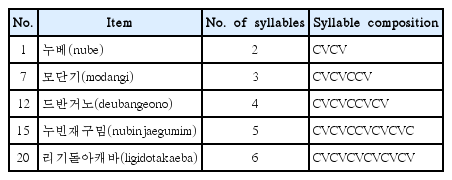
구어처리 과제로는 최근 언어문화적 배경이 다양한 언어장애 아동을 판별하는 데 유용하다고 보고된 바 있는 비단어따라말하기(NRT) 과제와 문장폭기억 과제(CLPT)를 실시하였다. 비단어따라말하기(NRT) 과제는 Lee (2010)의 연구를 수정·보완하였고 2음절에서 6음절 낱말이 각 4개씩 총 20개 단어로 구성하였으며 혹시나 다문화가정 아동 어머니의 모국어와 우연히 비슷한 단어일 가능성을 배제하기 위하여 다문화가정 아동 집단 어머니 6명(일본, 베트남, 필리핀, 태국, 중국, 몽골 출신)으로부터 모국어와 비슷한지를 5점 척도로 평가하도록 하여 모든 항목이 전혀 들어본 적 없는 새로운 낱말들임을 검증하였다. 본 과제의 비단어따라말하기 과제의 예는 Appendix 2에 제시하였다.
문장폭기억 과제(CLPT)는 선행연구(Gaulin & Campbell, 1994; Lee, 2004)를 참고로 연구자가 수정·제작하였다. 선행연구인 Oh와 Kim (2014)의 기준에 따라 3어절 문장으로 구성하였으며 어휘 빈도와 난이도는 학령 전 아동에게도 적절한 수준으로 통제하였고 각 단계별로 서술어의 종류(자동사/타동사/서술격 조사/형용사)가 골고루 포함되도록 고려하였고 정오반응의 정답 비율이 단계별로나 전체적으로 동일하도록 조정하였다. 선정된 문장들은 정오판단과 동시에 문장 마지막 낱말을 기억하도록 지시하였고, 단계별로 문장수를 기억해야하는 마지막 낱말의 수가 1개에서 6개까지 늘어나도록 6단계로 구성하여 각 단계의 마지막 문장의 정오판단이 끝난 후에 그 단계 문장(들)의 마지막 낱말을 모두 기억하도록 하였다. 즉, 1단계에서는 한 개의 문장을 들려준 후 바로 마지막 낱말을 회상하도록 하였으며, 6단계에서는 6개의 문장의 정오 판단이 끝난 후에 그 단계 문장의 마지막 낱말 6개를 모두 회상하도록 하였다. 문장폭기억 과제의 예는 Appendix 3에 제시하였다.
자료수집 절차
대상 아동의 선별검사와 자료수집은 서울, 인천 및 경기도의 방과후 교실(공부방) 또는 개별가정 방문형태로 실시되었다. 개별 가정집일 경우 조용한 방에서, 방과후교실의 경우 독립된 교실에서 아동과 일대일로 실시하였다.
기본 선별검사인 지능 및 학령기 언어검사는 대략 평균 1시간 40분-2시간 정도 소요되어 아동의 과제 집중력, 심리적 부담감, 방과후교실이나 아동의 개인 일정 등을 고려하여 1-2회기로 나누어 실시하였고, 나누어 실시하는 경우 두 검사 회기는 15일 이내가 되도록 조정하였다. 2회기로 나누어 실시하는 경우 1회기에는 수용 및 표현어휘력검사와 비단어따라말하기와 문장폭기억 과제를 실시하고, 2회기에 지능검사와 학령기아동언어검사를 실시하였다. 아동의 심리적 동기부여를 위하여 간헐적으로 강화물(간식)을 제공하였고, 자료수집 후 대상자들에게 1-2만 원 문화상품권을 제공하였다.
구어처리 과제는 컴퓨터화하여 연구자의 노트북 컴퓨터를 이용하여 컴퓨터 모니터 앞에 앞에 정면으로 앉아 모니터를 주시하면서 지시에 따라 키보드를 누르거나 마이크에 대답하게 하였다.
문화어휘 과제는 수용 및 표현어휘력검사(REVT)의 표현어휘검사 후 바로 표현어휘검사 실시 방법대로 실시하였다.
비단어따라말하기와 문장폭기억 과제는 E-Prime 프로그램(ver. 2)과 Cool Edit Pro (ver. 2; Adobe Systems, 2006)를 이용하여 컴퓨터 프로그램화하여 노트북으로 제시되었으며 아동은 헤드폰(Cre-syn CS-HP 500)을 쓰고 구어처리 과제의 낱말이나 문장을 듣고 말하도록 하여 녹음하였으며, 문장폭기억 과제의 정오반응이 자동으로 기록, 채점되도록 하였다.
자료의 분석 및 측정
어휘지식검사에서 REVT 수용 및 표현 점수는 최고한계선까지의 총점을, 문화어휘 점수는 전체 문항을 실시한 후 총점을 구하였다.
구어처리 과제는 비단어따라말하기(NRT)는 Dollaghan과 Campbell (1998), Rodekohr과 Haynes (2001)의 연구를 참고하여 정확하게 따라 말한 경우 1점을, 틀리게 말한 경우 0점으로 채점하되, 항목별 점수와 함께 한국어의 특성을 고려하여 음절단위 점수(개수, 비율)를 각각 구하였다(Lee, 2010). 경미한 조음 오류는 정반응으로 평가하였으나 대치나 생략은 오반응으로 평가하였다.
문장폭기억 과제(CLPT)는 문장의 의미에 대한 정오판단 점수와 함께 아동이 기억한 낱말의 수와 비율(%)을 구하였다. 아동반응에서 어간이 유지되는 시제나 어미 활용의 경우는 정반응으로 하였으나 동의어로 대치한 반응이나 서술격 조사의 ‘이다’만 산출하거나 품사를 바꾸어 산출한 경우는 오반응으로 처리하였다.
통계 분석
정상언어 집단과 언어장애 집단을 예측하는 요인을 분석하고, 각 변인들의 언어장애를 예측하는 회귀계수를 산출하기 위하여, SPSS version 18.0을 사용하여 각 어휘지식 과제 변인과 구어처리 과제 변인들을 독립변인으로 하고, 언어수준별 집단을 종속변인으로 하는 로지스틱 회귀분석을 실시하였다.
먼저 집단 간 차이를 보인 지능과 넓은 분포를 보였던 월령을 제어 변인으로 하여 모든 독립변인과 종속변인 간 편상관 분석을 실시하였다. 편상관 분석에 포함한 변인은 어휘지식 과제 변인(표현어휘검사, 수용어휘검사, 문화어휘검사)과 구어처리 과제 변인(NRT 항목점수, NRT 음절점수, CLPT 낱말회상점수, CLPT 정오판단점수)과 로지스틱 회귀분석의 종속변인인 언어수준별 집단(정상언어 집단, 언어장애 집단)이었다.
그런 다음 로지스틱 회귀분석으로 전체 변인과 어휘지식 과제변인, 구어처리 과제 변인 각각에서 언어장애를 예측하는 회귀모형과 유의미한 독립변인들의 승산비(odds ratio)를 산출하였다. 로지스틱 회귀분석에서는 각 과제별 분할점(cutoff point)에 따른 민감도(sensitivity)와 특이도(specificity)를 구할 수 있으나 본 연구의 목적은 과제별로 아동의 언어장애 여부를 판단할 수 있는 분할점을 구하는 것보다는 과제의 설명력을 알아보는 데 있었으므로 연속적인 분할점에서의 민감도를 Y축으로 1-특이도를 X축으로 하는 receiver operating curve (ROC)를 그려서 ROC curve 밑 공간의 면적(area under curve, AUC)으로 각 과제의 언어장애 여부 판단 정확도를 살펴보았다.
연구결과
편상관 분석결과
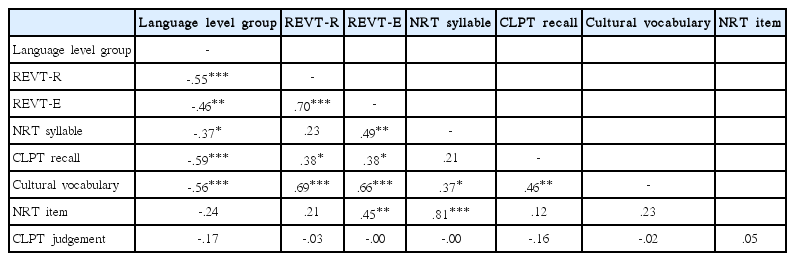
월령과 지능을 제어변인으로 하고 정상언어 집단과 언어장애 집단을 이분변인으로 하는 종속변인을 포함하여 변인들 간의 관계를 편상관 분석한 결과는 Table 3과 같다. 분석결과 NRT 항목 점수와 CLPT 정오판단 점수를 제외한 모든 독립변인이 종속변인과 유의한 상관을 보였다. REVT 수용어휘 점수, CLPT 낱말회상 점수, 문화어휘표현 점수는 유의수준 .001 수준에서 언어수준 집단과 유의한 상관을 보였으며, REVT 표현어휘 점수는 유의수준 .01 수준에서, NRT 음절 점수는 유의수준 .05에서 유의한 상관을 보였다.
Correlation between variables in all subjects
독립변인 간 상관을 살펴보면 NRT 음절 점수는 유의수준 .01에서 REVT 표현어휘 점수와 유의한 상관을 보였고 문화어휘표현 점수와의 상관은 유의수준 .05에서 유의하였다. CLPT 낱말회상 점수는 어휘지식 과제들과 고른 상관을 보였는데 REVT 수용 및 표현어휘 점수와는 유의수준 .05에서, 문화어휘표현검사 점수와는 .01 수준에서 유의한 상관을 보였다.
전체 독립변인을 대상으로 한 로지스틱 회귀분석
정상언어 집단과 언어장애 집단을 구분하는 결정 요인이 무엇인지 알아보기 위한 로지스틱 회귀분석 결과, NRT의 항목 점수를 제외한 어휘지식과 구어처리 과제의 모든 변인이 단일 투입시 언어장애 여부에 영향을 주는 것으로 나타났다.
모든 변인을 함께 투입하기 전 모든 변인에 대하여 분산팽창계수(variance inflation factor, VIF)를 산출한 결과, 표현어휘 점수는 6.87, 문화어휘표현 점수는 5.48, REVT 수용어휘검사 점수는 8.27, 월령은 2.84, 지능은 1.48, NRT 정확음절은 2.72, CLPT 낱말회상은 2.45로 VIF를 이용한 공선성 판단 기준인 10보다 작았다.
먼저 독립변인 모두를 선택하는 입력 방식으로 로지스틱 회귀분석을 실시하여 먼저 다른 변인이 설명하는 부분(공통변량)을 배제한 각 변인의 기여도를 살펴보고, 그런 다음 독립변인 선택방식을 전진-단계선택(우도비)로 하여 설명력이 높은 독립변인만을 모형에 포함하여 회귀식을 산출하였다.
편상관 분석 결과 등을 고려해 NRT의 항목 점수와 CLPT의 정오판단 점수를 제외한 모든 변인과 집단 간 차이를 보인 지능, 각 집단의 아동 연령대가 광범위한 점을 보정하기 위한 월령 변인을 입력 방법으로 투입한 결과, 월령(Wald= 6.11, p =.013), CLPT 낱말회상 점수(Wald= 4.64, p =.031)가 유의수준 .05에서 언어장애 여부에 유의하게 영향을 미치는 것으로 분석되었다. 그러나 NRT 음절 점수, REVT 표현어휘 점수, 문화어휘표현 점수, 지능 등은 언어장애 여부에 유의한 영향을 미치지 않았다. 독립변인을 입력 방법으로 투입하여 로지스틱 회귀분석한 결과는 Table 4와 같다. 그 결과, 월령이 한 단위 증가하면 언어장애 확률은 1.37배 증가하였고, CLPT 낱말회상 점수가 한 단위 증가하면 언어장애 확률은 0.52배 증가하였다.
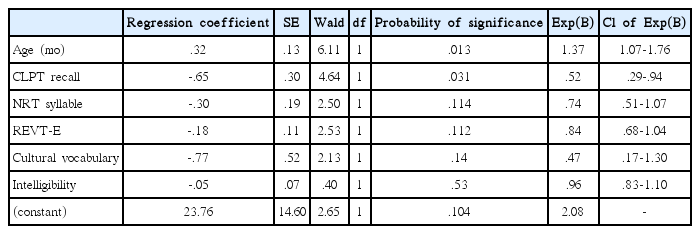
Logistic regression analysis of language disability of all variables
언어장애 여부를 효과적으로 예측하기 위한 회귀모형을 도출하기 위하여 설명력이 높은 변인만을 순차적으로 포함하는 전진-단계선택(우도비) 방법으로 회귀분석을 실시한 결과, 첫 번째로 CLPT 낱말회상 점수만을 포함하는 모형이 도출되었으며, 단계별로 순차적으로 월령, NRT 음절 점수 등이 포함된 모형이 도출되었다. χ2 값과 모형의 분류정확도, 모형에 포함된 변인의 유의확률 등을 고려하여 월령과 NRT 음절 점수, CLPT 낱말회상 점수를 포함하는 회귀모형을 선택하였으며, 모형의 검정과 분류정확도 결과는 Table 5와 같다. 월령과 CLPT 낱말회상 점수, NRT 음절 점수에 의해 언어장애 여부를 예측하는 모형은 유의수준 .05에서 통계적으로 유의미하였다. 또, 일반아동이 정확히 예측된 비율, 즉 민감도)는 93.3%, 언어장애 아동을 예측하는 특이도는 76.9%로, 전체적으로는 88.4%의 높은 분류정확도를 나타내었다.

Accuracy of classification of language disorder
언어장애 여부에 대한 개별 독립변인들의 통계적 유의성을 분석한 결과는 Table 6과 같다. 월령(Wald= 6.26, p =.012), CLPT 낱말회상 점수(Wald= 8.77, p =.003), NRT 음절 점수(Wald= 5.12, p = .024)는 모두 유의수준 .05에서 언어장애 여부를 설명할 수 있는 것으로 분석되었다.

Forward-stepwise logistic regression analysis for all variables
전체변인들에 대한 로지스틱 회귀분석에 의하여 도출된 회귀식은 다음과 같다.
Logit(언어장애) =15.63+.13(월령)+(−.55)(CLPT 낱말회상 점수)+ (−.32)(NRT음절 점수)
월령이 한 단위 증가하면 언어장애 확률은 1.14배 증가하고, CLPT 낱말회상 점수가 한 단위 증가하면 언어장애 확률은 0.58배 증가하고 NRT 음절 점수가 한 단위 증가할 때 언어장애 확률은 0.73배 증가한다. 이는 CLPT 낱말회상 점수, NRT 음절 점수의 승산비(odds ratio)를 통하여 이 두 과제에서의 점수가 높아지면 언어장애 집단으로 구분될 가능성보다는 정상언어발달 집단으로 구분될 확률이 증가함을 알 수 있다.
지금까지 살펴본 어휘지식 과제와 구어처리 과제에서 집단 간 차이를 보인 주요 요인에 대하여 연속적인 분할점 위치에 따라서 민감도와 특이도를 바탕으로 한 ROC 곡선 그래프를 Figure 1에 제시하였다.
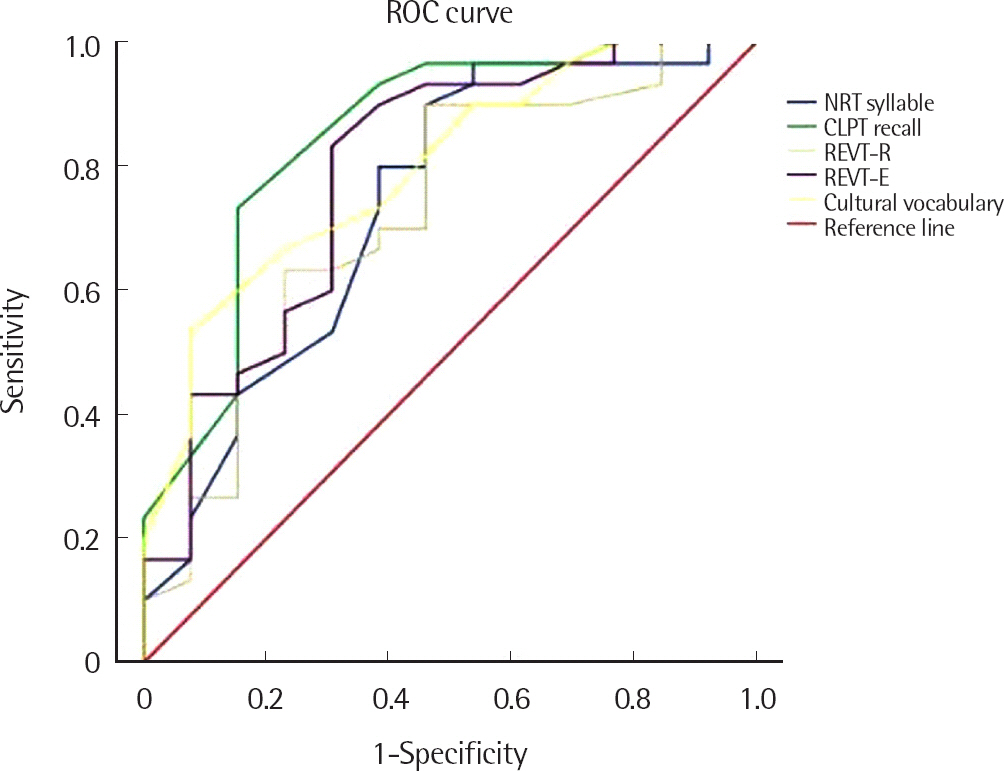
Receiver operating characteristic (ROC) curves for vocabulary knowledge tasks and language processing tasks. NRT=nonword repetition; CLPT=competing language processing task; REVT-R=Receptive & Expressive Vocabulary Test-Receptive vocabulary; REVT-E= Receptive & Expressive Vocabulary Test-Expressive vocabulary.
각 변인에 대한 곡선아래영역(AUC) 검정 결과는 Table 7에 제시하였다.
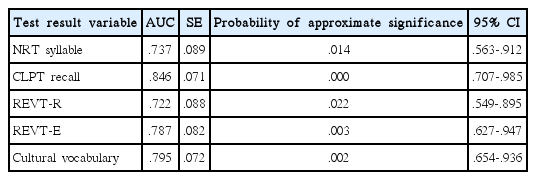
AUC of the variable
곡선아래영역을 비교하였을 때 CLPT 낱말회상 점수(AUC=.846, p< .001), 문화어휘표현 점수(AUC =.795, p < .01), REVT 표현어휘 점수(AUC =.787, p < .01), NRT 음절 점수(AUC = 737, p < .05), REVT 수용어휘 점수(AUC =.722, p < .05) 순으로 집단 구분 정확도가 높다고 평가되었으며, 모든 변인이 집단 구분에 유의하였다. 따라서 CLPT 낱말회상 과제는 AUC와 유의확률을 고려할 때 집단 구분에 좋은(good) 과제로, 나머지 모든 변인은 유용한(fair) 과제라고 할 수 있다.
논의 및 결론
본 연구는 학령기 다문화가정 아동의 언어장애 여부에 유의한 영향을 미치는 요인들을 밝히기 위해서 초등학교에 재학 중인 다문화가정 언어장애 아동 집단과 정상언어 집단, 일반가정 정상언어 집단에게 어휘지식 과제와 구어처리 과제를 실시하여 언어장애 여부를 예측할 수 있는 요인을 알아보고자 하였다.
정상언어 집단과 언어장애 집단을 구분하는 결정 요인이 무엇인지 알아보기 위한 로지스틱 회귀분석 결과, NRT의 항목 점수를 제외한 어휘지식과 구어처리 변인의 대부분이 단일 투입되었을 때에는 집단 구분에 영향을 주는 것으로 나타났다. 그러나, 어휘지식 과제와 구어처리 과제 변인을 입력방식으로 모두 투입한 로지스틱 회귀분석에서는 월령과 CLPT 낱말회상 점수 변인만이 유의수준 .05에서 언어장애 여부 결정에 유의하게 영향을 미치는 것으로 분석되었고, 다른 요인들은 로지스틱 회귀모형에 포함되지 못했다. 또한 언어장애 여부를 설명력이 큰 순서로 회귀모형에 투입하는 전진-단계선택 방법으로 도출한 회귀방정식에는 월령과 CLPT 낱말회상 점수, NRT 음절 점수가 유의한 변인으로 모형에 포함되었으며 전체 모형의 집단 분류정확률은 88.4%로 높았다. 특히 모든 변인을 대상으로 한 로지스틱 회귀분석에서 구어처리 과제 중 두 개의 변인이 언어장애 가능성을 예측하는 설명력이 큰 변인으로 분석되어 구어처리 과제의 언어평가 과제로서의 잠재력을 확인할 수 있었다.
같은 과제로 다문화가정 언어장애 아동과 정상언어 집단을 비교연구한 선행연구(Oh & Kim, 2014)에서 집단 간 유의한 차이를 보인 변인과 본 연구에서 언어장애 여부를 예측하는 데 높은 설명력을 보인 변인이 조금 달랐다는 점을 유의할 필요가 있다. 집단 간 차이 연구에서는 세 종류의 어휘지식 과제가 구어처리 과제에 비해 집단 간 차이를 뚜렷하게 보이는 변인이었고, NRT 음절 점수는 유의확률이 비교적 낮거나 다문화가정 정상언어 집단과 다문화가정 언어장애 집단 간 차이를 보이지 않았다. 그러나 본 연구의 로지스틱 회귀분석에서는 NRT 음절 점수가 CLPT 낱말회상 점수에 이어 설명력이 높은 변인이었다. 이는 물론 과제별 문항수와 각각의 통계분석 특성상의 차이에 기인한 것일 가능성도 있지만, 집단 간 유의한 차이를 나타내는 변인이라고 해서 반드시 그 변인이 두 집단을 구분하는 데 정확도가 높은 변인이라고 할 수 없음을 나타낸다(Dollaghan, 2004; Dollaghan & Horner, 2011). 즉, 집단 간 차이를 나타내는 변인을 진단에 사용하는 데 있어 좀 더 신중한 접근이 필요함을 시사한다고 하겠다.
근거기반평가(evidence-based evaluation)에서 어떤 과제에 대한 진단정확도 연구는 두 지표(indicators)나 측정치(measures), 프로토콜의 언어장애 집단 분류정확도에 따라 이루어져야 하고, 새 도구(index measures or comparator measure)를 신뢰할만한 기존 평가도구와의 결과 비교를 통해 이루어지게 된다(Dollaghan & Horner, 2011; Sackett et al., 2000), 이를 위해서는 우리나라 현실에서 언어장애를 구분할 수 있는 참조기준이 무엇인지에 대한 연구도 선행되어야 할 것이다. 본 연구대상 중 언어장애 집단을 나누는 데 있어서 표준화검사 결과와 함께 해외 문헌에서도 언어장애 변별의 참조기준으로 사용되는 1급 언어치료사의 임상적 판단에 의존했지만 참조기준에 대한 일치된 의견이 없는 한 진단정확도 연구에서 언어장애 집단 구분 기준에 대한 문제가 지속될 수밖에 없을 것이다. 특히, 의사소통장애 분야의 진단정확도 연구는 새로운 진단도구가 보완이 필요하다는 평가를 받은 기존 평가도구에 의해서 신뢰도가 평가되는 악순환이 생기기 쉽기 때문에(Dollaghan & Horner, 2011), 진단정확도 연구에서 표준화검사 결과 외에 언어장애 집단을 나누기 위한 보다 타당한 참조기준에 대한 충분한 논의가 필요하다. 따라서 앞으로의 후속연구를 통해 한국 아동이나 다문화가정 아동의 언어장애의 참조기준에 대한 모색이 선행되면서 다양한 과제들에 대한 진단정확도 연구가 병행되는 것이 바람직하다고 본다.
과제의 민감도와 특이도를 이용하여 그래프를 그려 집단 분류 효율성과 유용성을 시각적으로 나타내는 ROC curve에서는 CLPT 낱말회상 점수, 문화어휘표현 점수, REVT 표현어휘 점수, NRT 음절 점수, REVT 수용어휘 점수 순으로 집단 구분 정확도가 높다고 평가되었으며, 모든 변인이 집단 구분에 유의하였다.
영어-스페인어 이중언어 아동의 언어진단 연구들을 메타분석한 Dollaghan과 Horner (2011)에서는 비단어따라말하기, 낱말정의하기, T-unit당 오류율, 낱말정의하기, 스페인어 형태구문 검사, 과거시제, 발화길이, 부모보고, 가족력 등의 측정치가 우도비가 양호한 편이어서 언어결함을 판별하는 후보군들로 생각할 수 있다고 보았다. 하지만 이 중 어떤 변인도 그 한 가지 측정치가 최적의 방법으로 평가되지 않았고 이 측정치들은 다른 측정치로 보완되어야 한다고 보고하였다. 본 연구와 같은 유형의 과제를 사용한 Kohnert 등(2006)에서도 CLPT와 NRT 과제에서 영어 단일언어 아동과 영어 단일언어 사용 언어장애 아동과 영어-스페인어 이중언어 아동이 수행에 유의한 차이를 보였으나, 우도비 분석결과는 경쟁언어처리 과제(CLPT)와 비단어따라말하기(NRT)가 충분한 진단력(diagnostic power)을 가지고 있다고 보기는 어렵다고 결론지었다. 본 연구에서도 어느 한 가지 과제가 다른 과제들보다 다문화가정 아동의 언어장애 진단에 더 유용하다고 하는 주장하기는 어렵다. 같은 과제를 사용하여 집단 간 차이를 분석한 Oh와 Kim (2014)의 연구에서는 어휘지식 과제에서 더 뚜렷한 집단 간 차이를 보였으나, 본 연구의 회귀분석에서는 어휘지식 과제와 구어처리 과제 변인을 포함한 회귀모형들이 모두 집단 분류를 예측하는 유의한 요인이었으며, ROC curve 분석에서는 두 과제의 변인들이 고르게 집단 변별에 유용한 변인으로 분석되었다.
현재 다문화가정 아동의 언어평가의 경우 규준 집단의 구성이나 사용된 어휘나 과제 등이 다문화가정 아동에 불리할 수 있음을 알면서도 표준화 언어검사에 상당히 의존하여 진행되고 있다(Park & Jung, 2012; Pae, 2011). 본 연구는 다문화가정 언어장애 아동을 변별하는 데 어휘지식 과제가 어느 정도 유용한 진단도구로서의 가능성을 확인하였다는 데 의의가 있다고 하겠다. 또, 해외 다문화다언어 아동과 언어적 환경이 다른 우리 나라 다문화가정 아동에 구어처리 과제가 언어장애 진단 도구로서의 잠재력이 있음도 확인하였다. 이를 고려할 때 다문화가족지원센터 내 아동언어평가시 ‘음운기억과제’를 실시하게 되는 등 점차 구어처리 과제가 다문화가정 아동의 언어평가에 사용되고 있는 것은 바람직한 흐름으로 보인다(Korean Institute for Healthy Family, 2018).
구어처리 과제였던 비단어따라말하기는 언어권별로 언어적 특성에 따라 진단정확도 보고가 일관되지 않았는데(Stokes, Wong, Fletcher, & Leonard, 2006), 본 연구에서도 항목(낱말) 단위의 점수는 집단 간 차이나 회귀분석에서의 언어장애 설명력이 모두 유의하지 않았던 반면 음절 점수로는 집단 간 차이나 언어장애 여부 예측 또한 유의한 것으로 나타났다. 이는 우리나라 국어가 기본적으로 음소나 낱말보다는 음절 단위로 산출되는 언어이므로(Choi & Nam, 2002) 비단어따라말하기 과제 구성 시 기본 단위나 채점 방식에 있어 이를 고려하는 접근법이 필요할 것으로 생각된다.
그러므로 향후 다문화가정 아동의 언어진단 몇 평가 현장에서는 어느 한 과제가 다른 과제를 대체할 만한 진단평가로 보기보다는, 유용하다고 평가된 과제들을 종합하여 아동에 대해 판단하는 것이 바람직하다고 할 수 있겠다. 따라서 더 정확한 판별 요인에 대한 연구에서는 선행연구 결과를 참고하되 우리말 특성을 고려한 처리중심 평가를 개발하고, 구어처리 과제에 대한 보다 대규모 샘플을 통한 진단정확도 연구가 필요하다. 또한 선행연구에서 언급된 다른 유용한 가정 환경 측정치(부모보고, 가족력 등)나 자발화 측정치에 대한 진단 측정치로서의 연구도 지속되어야 할 것이다.
본 연구에서는 세 집단을 6개월 이내로 연령을 일치시키고 연령변인을 통제변인으로 통계처리하였지만 연령범위가 광범위하여 이에 따른 변인의 영향과 집단 특성이 달라질 수 있음을 완전히 통제할 수 없었다. 또한 연령당 아동수가 제한적이었으므로 학령기 아동에 연구결과를 일반화하는 데에는 제한이 있을 수 있다. 또, 학령기 언어장애 여부를 판단함에 있어 학령기 표준화 검사 이외에 학령기 아동에 대하여 언어장애 여부를 판단할 수 있는 공신력 있는 기준이 없어서 언어장애 집단 구분에 어려움이 있었다. 외국의 경우 학교 언어치료사에 의하여 치료에 의뢰되는 기준과 지역에 따라 언어장애 여부를 판단하는 법적 기준이 존재하지만 우리나라의 경우 학령기 아동에 대한 언어장애 여부 판단 기준이 없었기 때문에 집단 구분에 언어재활사의 주관적 판단이 개입되었을 가능성이 있다. 앞서 언급한 대로 구어처리 과제 같은 새 평가 과제를 포함한 진단 정확도를 표준화 검사로 검증하는 것은 바람직하지 않다고 보고되었다. Dollaghan (2004)에 의하면 집단 구분에 있어서 각 검사의 평가자를 다르게 하여 다른 평가의 결과를 모르는 상태에서 각 검사의 결과를 산출하고 이를 바탕으로 하여 집단 구분을 하는 것이 바람직한데 본 연구의 경우 과제별로 독립적인 판단을 하지 못하였다. 이후 학령기 아동을 대상으로 한 보다 다양한 표준화 검사의 개발과 언어장애 여부 판단 기준에 대한 연구가 필요하다. 또한 우리나라 다문화가정의 경우 소득 수준 외에도 어머니의 한국어 능력, 상호작용 스타일, 출신 국가 및 지역(도시/농촌) 등 다문화가정 아동의 언어발달에 영향을 줄 수 있는 요인이 많은데 본 연구에서는 대표적으로 소득 수준만을 고려하여 집단별로 통제하였다. 마지막으로 본 연구에서 구분한 구어처리 과제 변인은 어휘지식 변인과 상관관계가 높았다. 이후 구어처리평가와 어휘지식평가 구분의 타당도 검증을 위해서 요인분석 연구 등이 이루어져야 하고, 구어처리 과제가 실제로 무엇을 평가하는지, 다른 언어영역 평가와의 관련성도 연구가 이루어져 구어처리 과제가 표준화 언어검사의 대안적 평가방법인지에 대한 충분한 논의가 필요하다.