신경언어장애군의 동사 중재 자극 개발을 위한 기계학습 및 빅데이터 기반 한국어의 주격 및 목적격 명사 분석
Machine-Learning and Corpus-Based Analyses of Korean Nouns from Subjects and Objects: Stimuli Development of Verb Treatment for Neurogenic Communication Disorders
Article information

Abstract
배경 및 목적
본 연구는 신경언어장애군의 동사 중재 자극으로 쓰이는 동사의 주격 및 목적격 명사의 한국어 특징을 빅데이터 기반으로 분석하였다. 또한 분석한 원자료는 향후 동사 중재 관련 연구에 활용할 수 있도록 클라우드에 배포하여 공유하였다.
방법
교과서 말뭉치에서 목표 동사와 결합한 주격 및 목적격 명사 간 출현빈도수 및 유형수 차이를 분석하여 주어생략현상을 확인하였다. 또한 목표 동사로부터 주격 및 목적격 명사까지의 의미거리를 기계학습으로 산출하여 의미거리 분포 차이를 분석하였다. 더불어 기계학습으로 산출한 의미거리와 한국어 화자들이 인식하고 있는 의미거리 간 상관관계를 살펴보았다.
결과
주격 명사는 목적격 명사보다 유의하게 출현빈도수 및 유형수가 낮았으며, 동사와의 기계학습 기반 의미거리가 더 멀었다. 기계학습으로 산출한 의미거리는 행동데이터와 강한 정적 상관관계를 보였다.
논의 및 결론
본 연구에서 밝힌 한국어의 주어생략현상은 한국어를 사용하는 신경언어장애군의 특징을 설명하는 근거자료로 활용될 수 있다. 주격 명사와 동사 간 기계학습 기반 의미거리가 멀다는 결과는 앞으로 한국어를 사용하는 신경언어장애군을 위한 동사 중재에서 주격 명사의 활용 방안이 재고될 필요가 있음을 시사하였다. 더불어 기계학습으로 산출한 의미거리를 중재 자극 선정에서 하나의 기준으로 사용할 수 있는 가능성을 확인하였으나, 차후 정밀한 추가 검증이 필요하다.
Trans Abstract
Objectives
Subjects and objects associated with treatment verbs are common stimuli in verb treatment using the argument structure for neurogenic patients. This study investigated Korean nouns from subjects and objects associated with the target verbs in the corpus to suggest the characteristics of subjects and objects for developing Korean-specific verb treatment stimuli. In addition, we shared raw data through cloud so that anyone can use the data for clinical or academic purposes.
Methods
We used Korean textbook corpus to investigate the differences between subjects and objects in terms of frequency, number of type, and machine-learning based semantic distance to the target verbs. We also examined how machine-learning based semantic distance is correlated with behavioral rating semantic distance.
Results
Subjects significantly showed less frequency, less number of types, and farther machine-learning based distance to the target verbs than objects did. Machine-learning based semantic distance was strongly correlated with behavioral rating.
Conclusion
The results demonstrated strong evidence of the subject ellipsis phenomenon in Korean. The weak semantic relation, as proven by the machine-learning based semantic distance, indicated that subjects as verb stimuli for Korean-speaking neurogenic patients need to be reconsidered. We confirmed the possibility of machine-learning based semantic distance as a criterion in selecting the treatment stimuli, but more detailed verification is required for future studies.
신경언어장애군은 전반적으로 어휘 인출(lexical retrieval)에 어려움을 겪는다(Gillam, Marquardt, & Martin, 2011). 어휘 인출과 관련하여 다수의 실어증 환자군 연구에서는 실어증 유형에 따라 동사와 명사 인출의 해리(dissociation) 현상이 나타남을 보고하였다(Chen & Bates, 1998; Miceli, Silveri, Villa, & Caramazza, 1984; Zingeser & Berndt, 1990). 즉, 유창성 환자군은 동사보다 명사 인출을, 비유창성 실어증 환자군은 명사보다 동사 인출을 더 어려워한다는 것이다. 그러나 유창성 실어증 환자군 중 일부 베르니케실어증 환자들뿐만 아니라 정상 노년층도 동사 인출에 어려움을 겪는
다는 결과가 보고되면서 최근에는 명사보다 동사의 인출이 더 어렵다는 주장에 무게가 실리고 있다(Basso, Razzano, Fraglioni, & Zanobio, 1990; De Bleser & Kauschke, 2003; Luzzatti et al., 2002; Nicholas, Obler, Albert, & Goodglass, 1985).
동사 인출이 어려운 원인 중 하나로 동사가 명사 인출에 비해 더 많은 구문론적(syntactic) 처리를 요한다는 점을 들 수 있다(Kim & Thompson, 2000). 명사와 달리 동사는 특정 문장 성분(예: 주어, 목적어, 관형어, 부사어 등)과 함께 쓰여야지만 의미가 제대로 전달된다(Nam, 2004; Nam & Ko, 1993). 이때 동사가 필요로 하는 문장 성분을 동사의 ‘논항(argument)’이라고 하는데, 몇 개의 혹은 어떤 유형의 논항이 필요한지는 동사마다 다르다(Thompson, Lange, Schneider, & Shapiro, 1997). 동사의 인출에는 이와 같은 논항정보가 함께 인출되어야 하기 때문에 신경언어장애군의 동사 인출 중재법은 동사의 논항구조와 연관되어 다양하게 연구되어 왔다(Thompson & Shapiro, 2005, 2007; Thompson, Shapiro, & Roberts, 1993; Thompson, Riley, den Ouden, Meltzer-Asscher, & Lukic, 2013). 이 중에서도 특히 동사의 논항과 의미역(thematic role)을 중재 자극으로 활용하는 동사의미역강화중재(verb network strengthening)는 치료의 일반화 효과가 큰 것으로 알려져있다(Edmonds & Babb, 2011; Edmonds, Mammino, & Ojeda, 2014; Edmonds, Nadeau, & Kiran, 2009). 동사의 의미역이란 논항과 동사가 맺는 의미적 관계(semantic relation)를 일컫는다(Nam, 2007). 예컨대 ‘나는 밥을 먹는다’ 라는 문장에서 주어 ‘나’는 밥을 먹는 행동을 하는 ‘행동주(agent)’ 의미역이며, 목적어 ‘밥’은 행동주인 내가 먹는 ‘대상(theme)’ 의미역이다. 동사의미역강화중재에서는 주어와 목적어 두 개의 논항을 필요로 하는 2항 동사(2-place verb)를 사용한다. 그리고 그 동사의 주어 위치에 올 수 있는 주격 의미역 중 행동주와 목적어 위치에 올 수 있는 목적격 의미역 중 대상을 훈련하여 동사의 논항구조에 대한 인출을 촉진한다.
동사의미역강화중재는 한국어를 사용하는 소수의 실어증 환자군에게도 실행되어 중재 및 일반화 효과가 나타난 바 있다(Kwag, Sung, Kim, & Cheon, 2014). 한국어에서 동사는 대부분 문장의 맨 마지막에 위치하여 전체 문장의 의미를 결정하는 데 중요한 영향을 미치므로 중재의 필요성이 큰 품사이다(Son, 2001). 따라서 한국어 사용 실어증 환자군을 대상으로 한 동사의미역강화중재에서 중재 및 일반화 효과가 나타난 점은 매우 고무적이다. 그러나 동사 중재의 효과를 극대화하기 위해서는 한국어의 언어적 특수성이 고려되어야 하는데 이와 관련된 기초연구는 매우 부족한 실정이다.본 연구에서는 신경언어장애군의 동사 중재에 쓰일 수 있는 의미역 명사를 한국어 특징과 관련하여 분석하고자 한다. 이를 위해 우선 한국어의 특징인 주어생략현상(subject ellipsis)이 빅데이터 기반에서 확인되는지 살펴보고자 한다. 또한 동사와 의미역 간의 의미거리를 기계학습(machine learning) 기반으로 산출하고 그에 관한 기초자료를 클라우드에 공유하여 언어치료에 활용할 수 있도록 원자료를 배포하는 것에 목적이 있다.
본 연구의 첫 번째 목적은 한국어의 주어생략현상을 빅데이터 기반으로 살펴보는 것이다. 한국어의 특징 중 특히 주어생략현상이 동사의 논항구조에 미치는 영향에 대해 주시할 필요가 있다. 영어권 비유창성 실어증 환자군의 동사 산출은 동사의 논항수(number of arguments)와 관련되어 있는 것으로 나타났다. 즉, 영어권 비유창성 실어증 환자군은 논항수를 더 많이 필요로 하는 동사일수록 산출의 어려움을 보였다(De Bleser & Kauschke, 2003; Jonkers & Basttianse, 1996; Kemmerer & Tranel, 2000; Kim & Thompson, 2000). 반면 한국어 사용 경도인지장애군이나 실어증 환자군은 1항 동사와 3항 동사 간 산출에서만 유의한 차이를 보였다(Choi, Sung, Jeong, & Kwag, 2013; Sung, 2016). Sung (2016)은 그 원인 중 하나로 한국어 화자들이 2항 혹은 3항 문장에서 주어를 빈번히 생략한다는 점을 거론하였다. 즉, 한국어에서는 2항 동사가 주어 생략으로 인해 1항 동사처럼 기능하게 되어 1항 동사와 2항 동사의 산출 차이가 유의하지 않을 수 있다는 것이다. 한국어의 주어생략현상은 구어(spoken language) 및 문어(written language) 자료 분석에서 모두 밝혀진 바 있다(Kim, 2016; Kim & Choi, 2013; Lee, 2014; Park, 2012). 구어 연구의 경우 일상 대화를 분석하였다(Lee, 2014). 그러나 형식이 엄격하지 않은 구어의 특성상 주어생략현상이 빈번하게 일어났을 가능성이 있다. 문어 연구의 경우 소설, 사설, 영화 시나리오와 같이 제한된 장르에서만 주어생략현상이 밝혀졌다(Kim, 2016; Kim & Choi, 2013; Park, 2012). 이에 본 연구는 기존 연구와 비교하였을 때 매우 방대한 양일뿐만 아니라 다양한 글 종류를 포함하며, 아주 정제된 표현을 담고 있는 텍스트인 교과서에서도 주어탈락현상이 발생하는지 확인하고자 한다.
본 연구의 두 번째 목표는 교과서 말뭉치에서 동사와 주격 명사 간 의미거리 및 목적격 명사 간 의미거리를 기계학습으로 산출하고 그 특성에 대해 확인하는 것이다. 더불어 분석에 사용된 약 천 여개의 주격 명사와 목적격 명사의 목록은 언어치료사들이 중재자극 선정 과정에서 활용할 수 있도록 클라우드 기반(구글드라이브)으로 원자료를 배포하고자 한다. 기계학습이란 기계가 새로운 지식과 기술을 습득해나가는 과정을 통칭한다(International Organization for Standardization, 2015). 최근에는 기계학습을 통해 어휘를 숫자열 벡터(vector)로 나타내는 워드 임베딩(word embedding) 기술의 약진으로 어휘 간 의미 관계에 대한 정량적 파악이 가능해졌다(Mikolov, Sutskever, Chen, Corrado, & Dean, 2013a; Mikolov, Chen, Corrado, & Dean, 2013b). 이에 본 연구는 동사로부터 주격 및 목적격 명사까지의 의미 관계를 수치로 정량화(quantification)하여 의미거리 분포의 차이를 분석하고자 한다. 기계학습에 기반한 의미거리는 최근 가장 주목을 받고 있는 단어 임베딩 기술 중 하나인 Word2vec에 기반하여 구하고자 한다. Word2vec으로 임베딩한 단어 벡터들이 단어의 의미를 대변하고 있는지에 대한 검증은 여러 연구에서 시도되었다(Mikolov, Le, & Sutskever, 2013; Mikolov et al., 2013a; Mikolov, Yih, & Zweig, 2013d; Ororbia, Mikolov, & Reitter, 2017). 예를 들어, Mikolov 등(2013b)은 동일한 의미적 관계(semantic relation)를 가지는 여러 단어쌍들(예: ‘남자-여자’라는 의미적 관계를 가지는 ‘아들-딸’ 혹은 ‘손자-손녀’)을 얼마나 정확하게 유추할 수 있는지를 측정하였다. 이러한 연구들은 사람이 정의한 단어 간 의미 관계를 Word2vec이 학습한다는 점을 밝혔다는 데 의의가 있다. 그러나 의미거리를 치료에 활용하기 위해서는 한 단계 더 나아가 행동적(behavioral) 증거가 반드시 필요하나, 이와 관련된 연구는 찾아보기 어렵다. 따라서 본 연구에서는 기계학습으로 산출한 의미거리가 실제 한국어 화자들이 인식하고 있는 의미거리와 어떠한 상관관계를 보이는지 또한 검증하고자 한다.
요약하면, 본 연구의 목적은 한국어를 사용하는 신경언어장애군을 위한 동사 중재에 적용할 수 있도록 한국어 특성에 대한 기초연구를 시행하는 것이다. 보다 구체적으로는 치료 목표 동사 선정 후 이와 관련된 목표 동사의 주격 명사와 목적격 명사의 특징을 밝히고, 이에 대한 기초자료를 제시하는 것이다. 본 연구의 분석대상은 2항 동사의 주격 명사 중 의미역이 행동주인 명사, 그리고 목적격 명사 중 의미역이 대상인 명사이다. 단, 주격 조사 ‘이/가’나 목적격 조사 ‘을/를’이 명시적으로 붙은 명사로만 한정하였다. 본 연구의 연구질문은 아래와 같다.
첫째, 교과서 말뭉치에서 목표 동사와 결합하는 주격 및 목적격 명사의 평균 출현빈도수(frequency) 및 유형수(type)의 차이는 어떠한가?
둘째, 교과서 말뭉치에서 목표 동사로부터 주격 및 목적격 명사까지의 평균 의미거리(semantic distance)를 기계학습으로 산출하였을 때 그 분포의 차이는 어떠한가?
셋째, 기계학습으로 산출한 의미거리와 행동데이터 기반 의미거리의 상관관계는 어떠한가?
연구방법
실험 자극
목표 동사 선정
목표 동사는 한국어를 사용하는 신경언어장애군을 대상으로 한 동사 관련 선행연구 기반으로 선정하였다(선행연구 목록 및 선행연구 동사 목록은 Appendix 1 참고). 선행연구는 과제 유형에 따라 이해, 산출, 중재, 규준 연구로 분류되었으며, 언어적 수준에 따라 형태소, 단어, 문장, 이야기 수준으로 분류되었다. 동사 취합 시에는 과제 유형이나 언어적 수준에 제한을 두지 않고 단 한 번이라도 실험 동사로 쓰였을 경우 목표 동사에 포함하였다. 단, 기계학습으로 의미거리를 구하는 과정에서 오류를 야기할 수 있는 경우, 즉 (1) 동형이의어(homographic)인 형용사가 존재하는 동사(예: ‘쓰다’), (2) 합성 동사(예: 붙잡다), (3) ‘-하다’류 동사 (예: 참가하다), (4) 동사 활용에 의해 의미 오류가 발생할 수 있는 동사(예: ‘듣다’와 ‘들다’)는 목표 동사에서 제외하였다. 최종적으로 22개의 목표 동사가 선정되었다.
말뭉치 구성
본 연구는 두 개의 말뭉치를 구축하였다. 첫 번째 말뭉치는 ‘교과서 말뭉치’이다. 교과서는 비문(非文)이 적고 표현과 내용이 검증된 텍스트이므로 정제된 말뭉치에서 주격 및 목적격 명사의 특징을 밝히고자 한 본 연구의 목적에 부합하는 자료이다. 이에 교과서 말뭉치를 구축하여 교과서 말뭉치에서 목표 동사와 결합하는 주격 및 목적격 명사의 평균 출현빈도수 및 유형수의 차이를 구하였다. 두 번째 말뭉치는 ‘통합 말뭉치’이다. 통합 말뭉치는 교과서 말뭉치를 확장한 말뭉치이다. 교과서 말뭉치, 세종문어말뭉치, 그리고 한국어 위키피디아(Wikipedia) 말뭉치를 하나로 통합하였다. 세종문어말뭉치 및 한국어 위키피디아 말뭉치는 교과서 말뭉치보다 덜 정제된 성격의 문어 말뭉치이다. 그럼에도 불구하고 통합 말뭉치를 구축한 이유는 기계학습의 정확도를 높이기 위해서이다. 기계학습에서는 여러 용례를 학습할수록 어휘 간 의미관계를 좀 더 정확하게 파악하기 때문이다. 또한 통합 말뭉치는 기계학습으로 산출한 의미거리와 행동 데이터 간 상관관계를 분석하는 실험에서 설문 문항을 선정하는 데에도 사용하였다.
교과서 말뭉치
교과서 말뭉치는 중학교 국어교과서를 취합하여 구축하였다. 중학교 국어 수준으로 교과서 말뭉치를 구축한 이유는 중학교 교육 수준과 언어치료 대상자에게 기대하는 언어구사 수준이 근접하기 때문이다. 교육부에 따르면 중학교 교육의 목표는 ‘일상 생활과 학습에 필요한 기본 능력을 기르는 것’이다(교육부 고시 2015개정교육과정 제2015–74호 [별책3]에 의거함). 반면 초등학교 국어교과서의 경우 학년 간 텍스트의 수준 차이가 커서 선택하는 데 부적절하였고, 고등학교 국어교과서의 경우 일상 생활의 필요성과 수준을 넘어서는 문법 및 고전문학의 비중이 컸기 때문에 제외하였다. 교과서 말뭉치는 2009학년도 검·인정 중학교 국어 교과서 7종—창작과 비평, 교학사(남미영), 미래엔(윤여탁), 신사고(민현식), 신사고(우한용), 비상교육(김태철), 비상교육(한철우)—을 취합하였으며, 교과서 간 중복된 텍스트는 하나만 남기고 삭제하였다. 중복 텍스트의 목록은 Appendix 2에 제시하였다.
목표 동사의 주격 및 목적격 명사 추출
교과서 말뭉치에서 목표 동사와 결합하는 주격 및 목적격 명사를 추출하기 위해 ‘꼬꼬마(KKMA) 구문 분석기 버전 2.1’를 사용하였다. 이때 명사의 품사는 일반명사로 제한하였다. 최종 선정된 통사구조는 참고자료로 활용할 수 있도록 본 연구에서 분석한 출현 빈도수, 기계학습으로 산출한 의미거리 정보와 함께 구글드라이브(https://docs.google.com/spreadsheets/d/1Me7_lJ7r9gqSX-HwTmIqHL1ZhG5dMFFWwmkXQ4DpNKs/edit?us p = sharing)에 게시하였다.
실험 절차 및 분석
목표 동사와 결합하는 주격 명사와 목적격 명사의 평균 출현 빈도수 및 유형수 차이
평균 출현빈도수란 교과서 말뭉치에서 각 목표 동사와 결합한 주격 혹은 목적격 명사가 평균 몇 회 출현하였는지를 의미한다. 평균 유형수란 각 목표 동사와 결합한 주격 혹은 목적격 명사가 평균 몇 종이었는지를 의미한다. 추출한 주격 명사 총 258개, 목적격 명사 총 4,722개에 대하여 평균 출현빈도수 및 유형수 차이를 분석하였으며, 이때 평균 출현빈도수 및 유형수는 Python으로 계산하였다.
목표 동사로부터 주격 명사와 목적격 명사까지의 의미거리 분포의 차이
교과서 말뭉치에서 목표 동사와 결합한 서로 다른 주격 및 목적격 명사에 대하여 각 목표 동사별 평균 기계학습 기반 의미거리를 구하였다. 주격 명사 총 139개, 목적격 명사 총 1,002개가 분석 대상이 되었다. 기계학습 기반 의미거리 산출 과정은 다음과 같다.
워드 임베딩(Word Embedding)
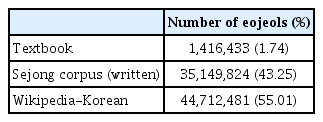
어휘를 숫자열로 벡터화(vectorize)하는 워드 임베딩 방식은 여러가지가 있는데, 이 중 학습 속도를 현저히 개선한 Word2vec이 널리 쓰인다(Mikolov et al., 2013a). 이에 본 연구는 Word2vec으로 워드 임베딩을 수행하였다. Word2vec은 띄어쓰기를 기준으로 어휘를 구분하여 벡터를 산출한다. 예를 들어 ‘거짓말이 거짓말을 낳았다’라는 문장을 학습하면 띄어쓰기 단위로 세 개의 어휘(‘거짓말이’, ‘거짓말을’, ‘낳았다’)에 대한 벡터가 각각 산출된다. 본 연구는 먼저 통합 말뭉치를 꼬꼬마 구문분석기로 형태소 태깅(tagging)하여 형태소 단위로 띄어쓰기를 하였다. 즉, ‘거짓말이 거짓말을 낳았다’라는 문장은 형태소 태깅 후 ‘거짓말/NNG 이/JKS 거짓말/NNG 을/JKO 낳/VV 았/EPT 다/EFN’가 된다. 형태소 태깅의 목적은 목표 동사의 벡터를 어근 기준으로 산출하기 위함이다. 그리하여 동사의 활용형(예: ‘낳다’의 경우 ‘낳았다’ 등)마다 각각의 벡터가 산출되는 것을 방지하였다. 형태소 태깅 후에는 체언(보통명사, 고유명사, 대명사, 의존명사, 수사, 일반명사)과 조사(격조사, 보조사, 접속조사)를 붙였다. 즉, 앞의 예시 문장은 최종적으로 ‘거짓말이/ NNG/JKS 거짓말을/NNG/JKO 낳/VV 았/EPT 다/EFN’가 된다. 체언과 조사를 붙인 이유는 명사가 주격 명사로 쓰였을 때와 목적격 명사로 쓰였을 때를 구분하여 벡터를 산출하기 위함이다. 또한 Word2vec은 매개변수(parameters) 조정을 통해 학습기준을 달리할 수 있다. 이에 Gensim3.2.0으로 매개 변수를 바꾸어가며 말뭉치를 학습해 보았다. 결과적으로 단어 간 관계가 가장 잘 학습되었던 매개변수 값을 택하였으며, 그 값은 Table 2에 제시하였다. 각 매개 변수가 의미하는 바는 Goldberg와 Levy (2014)의 연구에 자세히 설명되어 있다.
Parameters setup for Word2vec
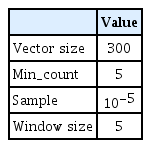
Word2vec으로 임베딩한 단어들의 벡터를 다차원의 벡터 공간에 투영(project)하면 Figure 1처럼 비슷한 의미적 특성을 지닌 단어끼리 군집하여 분포하게 된다(Mikolov et al., 2013d). 따라서 임베딩 후 단어 벡터 간의 차이는 두 단어 간의 의미적 특성을 반영하는 ‘의미거리’라고 정의할 수 있다.
Example of the distribution of words in the multi-dimensional vector space after producing word embeddings by Word2vec. Words with similar semantic features are clustered as a result of Word2vec.
어포던스 벡터(Affordance vector)
워드 임베딩 후 다차원의 벡터 공간에서 명사는 자신과 결합이 가능한 동사들과 Figure 2A처럼 일정한 거리를 유지하고 있다. 이때, ‘명사-결합 가능한 동사 집단’ 사이의 평균 델타(delta)를 ‘어포던스’라고 한다. 따라서 Figure 2B처럼 다차원의 벡터 공간에 위치한 명사의 벡터에 결합 가능한 동사들과의 어포던스 벡터만큼을 더해주면, 명사는 결합 가능한 동사들이 군집해 있는 방향으로 이동(translation)한다(Fulda, Ricks, Murdoch, & Wingate, 2017). 본 연구에서도 어포던스 벡터를 사용하였다. 단, 본 연구에서는 명사가 아닌 목표 동사의 벡터를 이동시켰다. 즉, Word2vec으로 구해진 목표 동사의 벡터에 주격 명사와의 평균 어포던스나 목적격 명사와의 평균 어포던스를 빼주어 목표 동사를 각 명사가 군집해 있는 방향으로 이동시켰다.
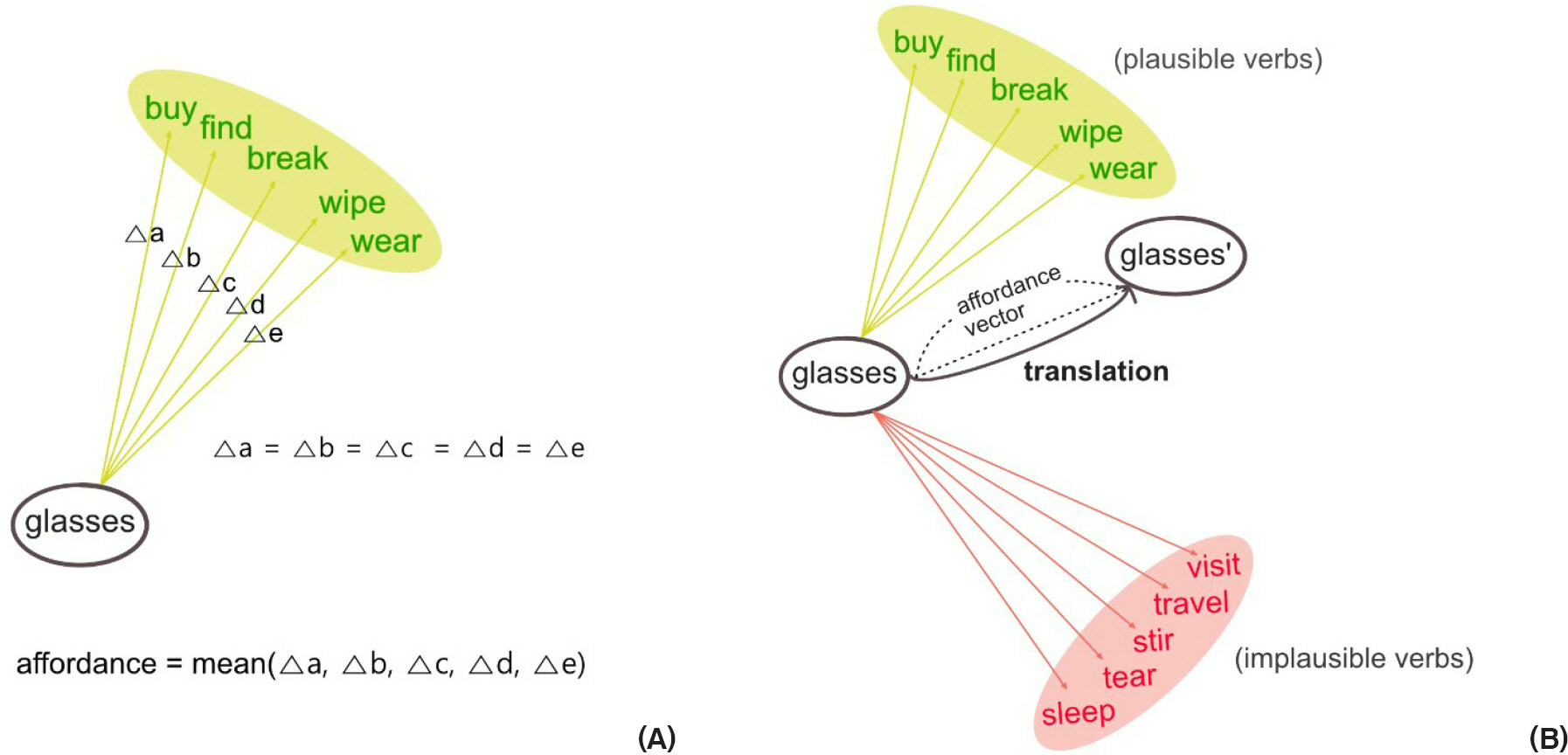
Example of affordance between a noun and verbs (A) and translation (B). (A) The mean delta (Δ) between a noun and its plausible verbs is called affordance. (B) Semantically implausible verbs with noun glasses are clustered at the bottom (red), whereas semantically plausible verbs are clustered on the top (green). After vector glasses are translated with the amount of affordance vector, the glasses move toward the vector space where their plausible verbs are clustered.
코사인 유사도(Cosine similarity)
목표 동사를 결합 가능한 주격 혹은 목적격 명사들의 군집으로 이동시킨 후, Gensim으로 목표 동사와 명사들 간 코사인 유사도를 계산하였다. 코사인 유사도는 다차원의 벡터 공간에서 두 벡터 간의 거리를 계산하는 여러 방법 중의 하나이다. 두 벡터의 내적(dot product)으로 두 벡터가 이루는 각(angle)을 측정하며, 각이 클수록 두 단어의 거리가 먼 것으로 계산된다. 코사인 유사도값은 −1과 1사이로, −1에 가까울수록 의미거리가 멀고 1에 가까울수록 의미거리가 가깝다는 것을 의미한다.
기계학습 기반 의미거리와 행동데이터 기반 의미거리 간
상관관계
연구 대상 기계학습으로 산출한 의미거리와 사람이 실제 인지하는 의미거리와의 상관관계를 알아보기 위해 20–30대 정상청년층 123명을 대상으로 구글 온라인설문을 실시하였다. 연구참여자의 평균 연령은 29.0세(SD = 4.4; range, 21–37세), 평균 교육년수는 15.4년(SD =1.1; range, 9–16년), 남녀의 성비는 0.86:1이었다. 이때 발달성 장애력이 있는 경우, 모국어가 한국어가 아닌 경우는 설문 대상에서 제외하 였다. 더불어 본 연구는 중학교 교과서 말뭉치에 기반하였으므로 피험자는 반드시 한국에서 중학교를 재학해야 했으며, 초등학교를 4년 이상 외국에서 다닌 경우도 제외하였다. 본 연구는 이화여자대학교 생명윤리위원회의 승인을 받아 진행하였다(No. 130–15).
설문 문항 구성
설문 문항은 통합 말뭉치에서 목표 동사와 기계학습에 기반한 의미거리가 최소·최대인 주격 명사를 1개씩, 목적격 명사를 1개씩 선정하였다. 의미거리가 최대인 명사는 목표 동사와 의미적으로 가장 먼 명사이므로 실제 언어 생활에서 쓰이지 않는 통사구조가 설문 문항이 되기도 하였다(예: ‘폭풍을 가르치다’). 명사 선정 과정에서 (1) 다의어, (2) 고유어로 대체할 수 없는 외래어(예: ‘벨브’), (3) 문맥없이 이해가 어려운 명사(예: ‘방도’), (4) 불쾌감을 주는 명사(예: ‘시신’), (5) 표준국어대사전에 등재되지 않은 명사, (6) 통합 말뭉치에서 5회 미만 등장하여 벡터가 산출되지 않은 명사는 제외하였다. 최종적으로 18개 동사에 대해 네 가지 조건(‘주격 명사-목표 동사 의미거리 최소’, ‘주격 명사-목표 동사 의미거리 최대’, ‘목적격 명사-목표 동사 의미거리 최소’, ‘목적격 명사-목표 동사 의미거리 최대’)에서 각 한 문항씩, 총 72문항으로 설문 문항을 구성하였다. 전체 설문 문항은 Appendix 3에 제시하였다.
실험참여자는 제시된 명사와 동사가 의미적으로 얼마나 관련이 있는지를 Likert 5점 척도로 평정하였다. 설문은 네 개의 섹션(section)으로 나누어졌으며, 각 섹션마다 4–5개의 동사에 대한 설문이 포함되었다. 홀수 섹션에는 주격 명사가, 짝수 섹션에서는 목적격 명사가 먼저 제시되었다. 본 연구의 목표 동사는 주격 및 목적격 명사가 모두 필요로 하는 2항 동사였다. 따라서 ‘주격 명사-목표 동사’ 혹은 ‘목적격 명사-목표 동사’로만 설문 문항을 제시할 경우 설문 문항이 비문(非文)이 되어 어색하였다. 이에 주격 명사 설문에서는 목적어 위치에 ‘(∼를)’을, 목적격 명사 설문에서는 주어 위치에 ‘(∼가)’를 추가하여 설문 문항을 제시하였다. 설문의 예시는 Figure 3에 제시하였다.
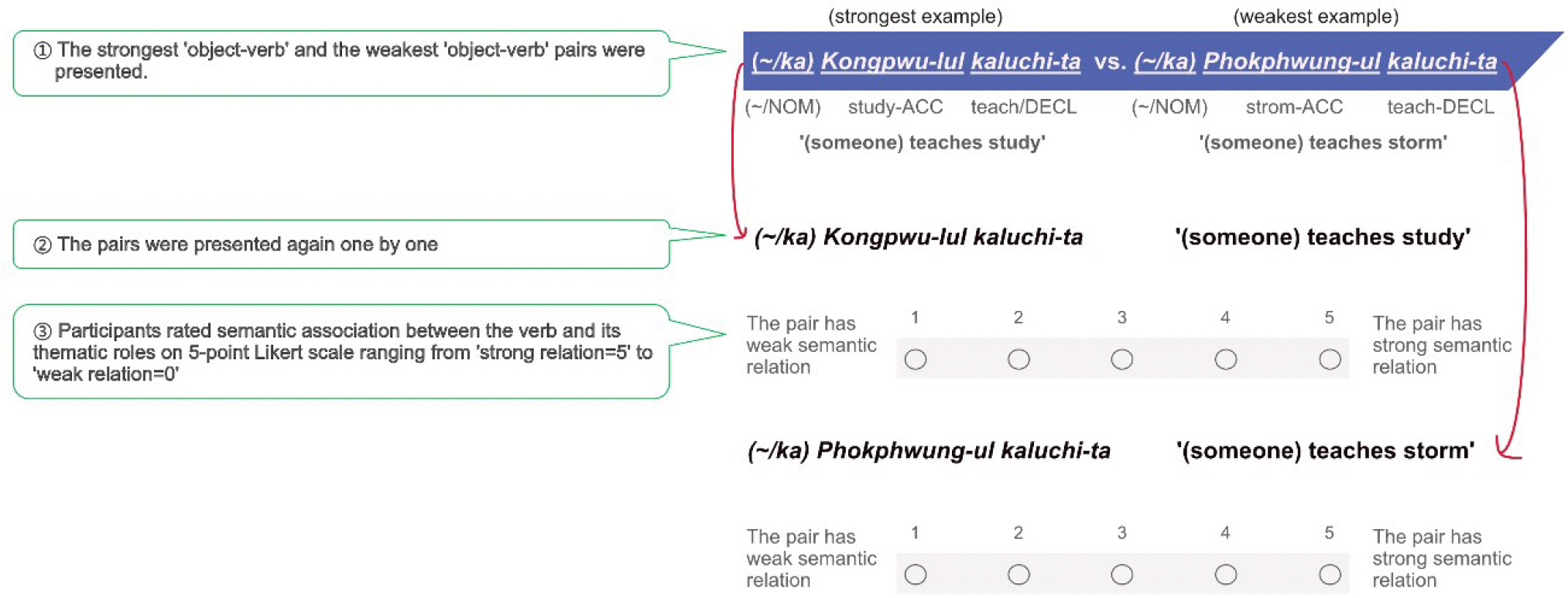
Example of a Google survey. Yale Romanization of Korean is used in transcribing the Korean alphabet (Martin, Yi, & Chang, 1967).
자료의 통계적 처리
목표 동사와 결합하는 주격 명사와 목적격 명사의 평균 출현빈도수 및 유형수의 차이, 그리고 목표 동사로부터 주격 및 목적격 명사까지의 평균 기계학습 기반 의미거리 차이를 알아보기 위해 IBM SPSS Statistics version 20으로 대응표본 t-검정(paired t-test)을 실시하였다. 이때 평균에서 3 SD 이상 떨어진 이상치(outlier)는 제거 후 분석하였다. 기계학습으로 산출한 의미거리와 행동데이터 기반 의미거리의 상관관계 분석은 각 의미거리를 표준화 점수(z-score)로 변환한 후 SPSS로 Pearson 상관분석을 실시하였다.
연구결과
목표 동사와 결합하는 주격 및 목적격 명사의 평균
출현빈도수와 유형수의 차이
출현빈도수 이상치(>3 SD)를 제외한 결과 교과서 말뭉치에서 총 19개의 목표 동사가 분석에 포함되었다. 목표 동사와 결합하는 주격 명사는 총 121개, 목적격 명사는 총 1,237개가 추출되었다. 각 목표 동사별 주격 및 목적격 명사의 평균 출현빈도수를 알아보기 위하여 대응표본 t-검정을 실시하였다. 그 결과, 목표 동사별 주격 명사의 평균 출현빈도수(6.37±1.50)가 목적격 명사의 평균 출현빈도수(65.11±66.35)보다 유의하게 낮았다(t18 = −4.171, p < .005). 주격 및 목적격 명사의 평균 출현빈도수에 대한 상자도표(boxplot)는 Figure 4A 에 제시하였다.
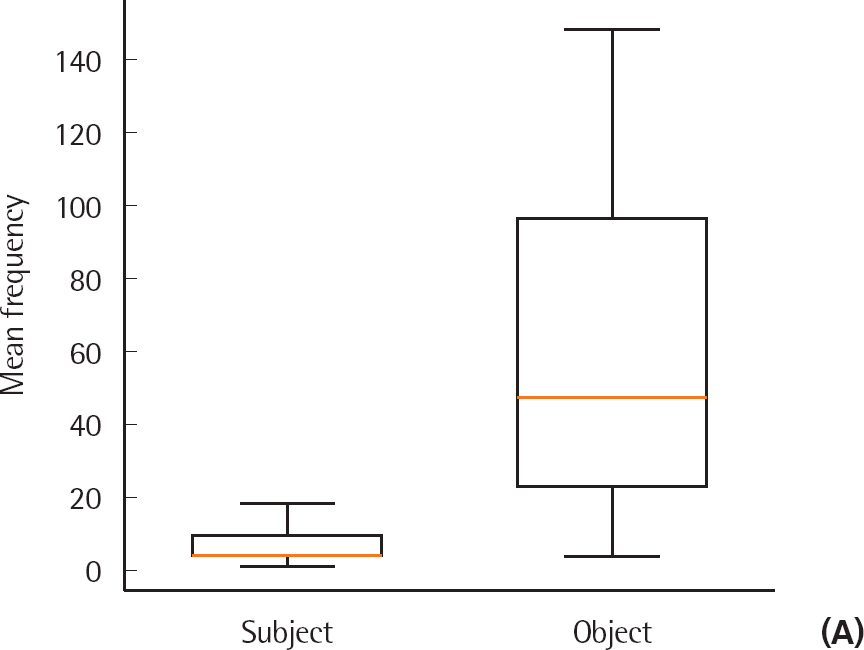
Boxplots of the mean frequency (A) and the mean number of types (B).
유형수
이상치를 제외한 결과 총 20개의 목표 동사가 분석에 포함되었다. 목표 동사와 결합하는 주격 및 목적격 명사 중 서로 다른 유형수의 주격 명사 총 105개, 목적격 명사 총 708개가 추출되었다. 각 목표 동사별 주격 및 목적격 명사의 평균 유형수를 알아보기 위하여 대응표본 t-검정을 실시하였다. 그 결과, 주격 명사의 평균 유형수(5.25±4.40)가 목적격 명사의 평균 유형수(35.40±39.37)보다 유의하게 낮았다(t19 = −3.766, p < .005). 주격 및 목적격 명사의 유형수에 대한 상자도표는 Figure 4B에 제시하였다.
‘목표 동사-주격 명사’와 ‘목표 동사-목적격 명사’의 기계학습 기반 의미거리 차이
이상치를 제외하고 교과서 말뭉치에서 21개의 목표 동사와 결합한 주격 명사(N=124)와 목적격 명사(N= 814)를 대상으로 의미거리를 산출하였다. 각 목표 동사에서 주격 및 목적격 명사까지의 평균 기계학습 기반 의미거리의 분포 차이를 알아보기 위하여 대응표본 t-검정을 실시하였다. 기계학습으로 산출한 의미거리는 −1부터 1사이의 값을 가지며, 1에 가까울수록 의미거리가 가까운 것으로 해석한다. 분석 결과 목표 동사와 주격 명사의 평균 의미거리(0.33±0.08)가 목표 동사와 목적격 명사의 평균 의미거리(0.38±0.06)보다 유의하게 먼 것으로 나타났다(t20 = −3.325, p < .005). 기계학습으로 산출한 의미거리에 대한 상자도표는 Figure 5에 제시하였다.
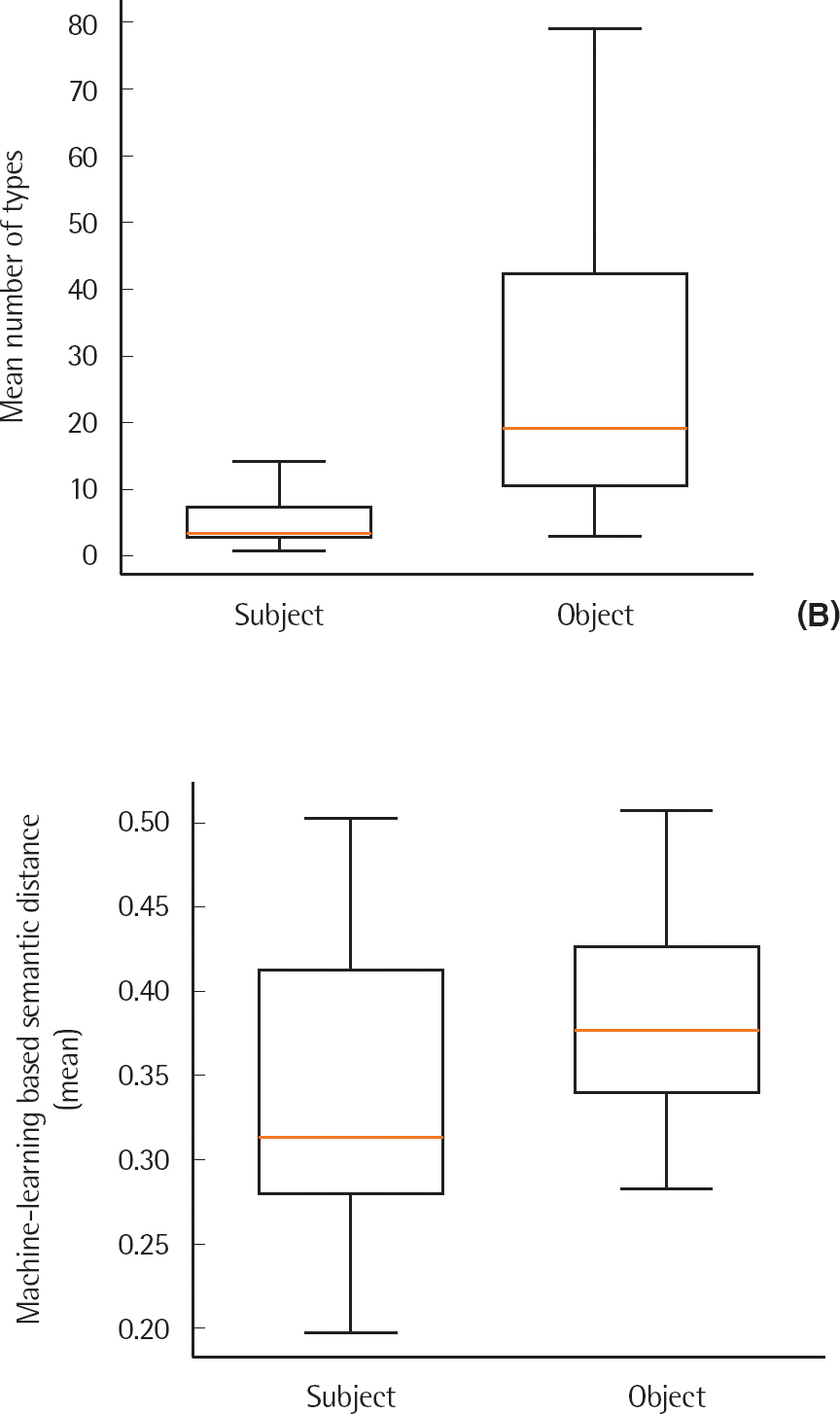
Boxplots of the mean machine learning-based semantic distance to the target verbs
기계학습으로 산출한 의미거리와 행동데이터 기반 의미거리의 상관관계
기계학습으로 산출한 의미거리와 행동데이터 기반 의미거리 간 상관관계 분석을 위해 Pearson product-moment을 사용하였다. 그 결과, 기계학습으로 산출된 의미거리와 행동데이터 기반 의미거리 간 상관관계는 주격과 목적격 모두에서 매우 강한 정적(positive) 관계를 보이는 것으로 나타났다(주격명사: r =.806, p < .001, 목적격명사: r =.930, p < .001). 기계학습으로 산출한 의미거리와 행동데이터 기반 의미거리의 산점도(scatter plot)는 Figure 6에 제시하였다.
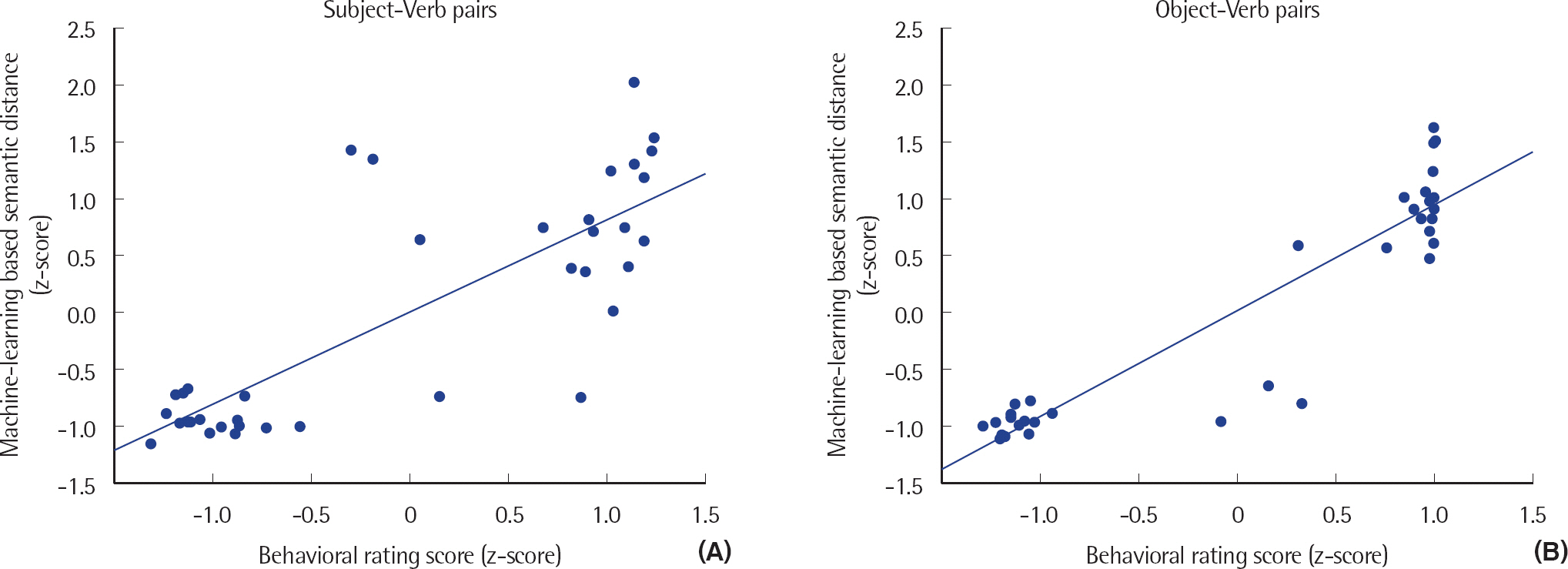
Scatter plots of the correlation between machine learning-based semantic distance and the behavioral distance rating score: subject–verb pairs (A) and object–verb pairs (B).
논의 및 결론
본 연구는 한국어를 사용하는 신경언어장애군의 동사 중재에서 중재 자극으로 사용될 수 있는 한국어 주격 및 목적격 명사에 대한 기초자료를 빅데이터 기반으로 분석하고 원자료를 제공하고자 하 였다. 이를 위해 교과서 말뭉치를 분석하여 목표 동사와 결합하는 주격 및 목적격 명사의 평균 출현빈도수, 그리고 유형수 차이를 규명하였다. 또한 목표 동사로부터 주격 및 목적격 명사까지의 평균 의미거리를 기계학습으로 산출하여 의미거리의 분포 차이를 분석하였다. 더불어 기계학습으로 산출한 의미거리와 행동데이터 기반 의미거리의 상관관계를 밝혀 방법론에 대한 검증을 수행하였다.
분석 결과 주격 명사는 목적격 명사보다 평균 출현빈도수 및 유형수가 모두 낮은 것으로 드러났다. 대규모 텍스트 자료에서, 특히나 정제된 표현이 담긴 교과서 말뭉치에서 주어생략현상이 일관되게 나타난다는 점은 주목할 필요가 있다. 교과서보다 표현의 제약이 엄격하지 않은 여타의 문어 말뭉치나 구어 말뭉치에서는 주어의 생략이 더욱 빈번할 것임을 예상할 수 있기 때문이다. 앞서 한국어 사용 경도인지장애군 및 실어증 환자를 대상으로 동사 논항수에 따른 산출 과제를 수행하였을 때 1–3항 동사 간의 산출만 유의하게 어려움이 증가하는 현상이 나타난다고 하였다(Choi et al., 2013; Sung, 2016). 그리고 Sung (2016)은 그 원인을 한국어 2항 동사에서의 잦은 주어생략현상으로 해석하였다. 의미역 선택 과제에서도 주어의 빈번한 생략이 정반응률에 영향을 미치는 것으로 논의된 바 있다. Jeong과 Sung (2018)은 한국어 사용 실어증 환자군과 정상 집단에게 여러 유형의 명사를 제시한 후 그 안에서 동사의 주격 의미역(행위자)과 목적격 의미역(대상)을 선택하는 과제를 수행하게 하였다. 그 결과 두 집단은 모두 동사의 행위자를 선정하는데 더 어려움을 겪었으며, 이는 구어에서 주어의 생략 비율이 높은 한국어의 특징에 기인한 것으로 보았다(Jeong & Sung, 2018). 이처럼 지금까지 주어생략현상은 한국어를 사용하는 신경언어장애군의 동사 관련 연구에서 가설로만 제기되었다. 그러나 본 연구는 주어생략이 빅데이터에서 확인할 수 있는 현상임을 밝혔다는 점에서 의의가 있다. 즉, 이러한 결과는 임상적 현상을 빅데이터 기반으로 설명할 수 있는 기초자료를 제공하였다는 점에서 의미가 있다. 앞으로도 본 연구 결과는 동사 논항이나 의미역과 관련하여 한국어를 사용하는 신경언어장애군이 보이는 한국어 특정적(Korean-specific) 현상에 대한 근거자료로 활용될 수 있을 것이다.
기계학습으로 산출한 의미거리 분석에서는 주격 명사가 목적격 명사보다 동사와의 의미거리가 먼 것으로 드러났다. 이는 앞서 밝힌 주어생략현상이 반영된 결과로 보인다. 즉, 주어가 자주 생략되는 한국어 특성상 주어가 동사와 결합하는 빈도가 낮아지고 의미거리도 멀어지는 것으로 해석된다. 따라서 한국어를 사용하는 신경언어장애군을 대상으로 하는 동사 중재에서 주어 활용 방안에 대한 고찰이 필요하다. 예를 들어, 영어권 실어증 환자군을 대상으로 한 동사의미역강화중재에서는 주격 및 목적격 의미역을 동등한 빈도로 치료를 진행한다(Edmonds & Babb, 2011). 한국어 사용 실어증 환자군을 대상으로 한 동사의미역강화중재연구에서도 영어권 환자와 동일한 중재법을 적용하였다(Kwag et al., 2014). 하지만 주어 탈락이 빈번하고 주격 명사-동사의 의미거리가 먼 것을 빅데이터 기반으로 밝힌 본 논문의 결과를 감안할 때, 다음과 같은 임상적 시사점이 있다. 한국어에서는 주격 명사를 중재자극으로 목적격 명사와 자극 빈도를 동일하게 치료하는 것은 동사 중재 효율성의 문제를 야기할 수 있다. 세종 구어 말뭉치 자료에서 주어생략현상을 분석한 Lee (2014)에 따르면 일반적인 대화 상황에서 한국어 화자는 1·2인칭 주어를 쓰지 않으며, 화용적(pragmatics) 의도가 있을 때만 주어를 명시한다고 하였다. 본 연구에서도 주격 명사는 빈번히 생략되며 동사와의 의미거리가 멀었다. 따라서 한국어를 사용 하는 신경언어장애군을 치료할 때 주격 이외의 논항으로 동사의 논항구조를 활성화시켜 중재 및 일반화 효과를 극대화하는 한국어 특성을 반영한 중재 프로토콜을 개발할 필요가 있다. 예를 들어, 여격(−에/에게), 탈격(−에서/에게서), 방향격(−로/으로)을 논항으로 취하는 3항 동사의 활용 방안을 고려할 수 있다.
기계학습으로 산출한 의미거리와 행동데이터 기반 의미거리의 상관관계는 매우 강한 정적 상관관계를 보였다. 즉, 기계학습 기반 의미거리가 실제 한국어 화자가 느끼는 의미거리와 관련성이 높다는 것을 입증하였다. 최근 국외에서는 신경언어장애군을 대상으로 한 기계학습 연구가 다양하게 이루어지고 있으며, 본 연구에서처럼 기계학습 결과를 행동데이터로 증명하고 있다(Kiran & Thompson, 2003; Le, Licata, Mercado, Persad, & Provost, 2014). 기계학습 데이터로는 컴퓨터 단층촬영(computed tomography, CT) 결과 및 신경심리검사 결과, 자발화 등의 자료를 이용한다. 그리하여 기계학습 결과를 바탕으로 신경언어장애군의 진단 시 활용할 수 있는 분류기준(classifier)을 찾고, 자동으로 환자의 임상적 진단을 내리기 위한 시스템을 개발하려는 시도가 주를 이루고 있다(Bentley et al., 2014; Fraser et al., 2014; Garrard, Rentoumi, Gesierich, Miller, & Gorno-Tempini, 2014; Järvelin & Juhola, 2011; Orimaye, Wong, Golden, Wong, & Soyiri, 2017). 기계학습 결과를 치료에까지 적용한 연구도 있다(Kiran & Thompson, 2003). Plaut (1996)은 컴퓨터 모의 실험으로 단어의 전형성(typicality)이 치료 일반화에 미치는 영향을 분석한 바 있다. Plaut (1996)은 먼저 컴퓨터 네트워크에 단어의 의미(semantic) 정보를 학습시킨 후, 학습 내용을 다시 의도적으로 손상시키고 재학습시켰다. 그 결과, 비전형적(atypical) 단어들(예: ‘새’라는 범주에서 펭귄)을 먼저 재학습시키면 전형적(typical) 단어들(예: ‘비둘기’)을 인식하는 데 향상이 나타났다. 반면 전형적 단어들을 먼저 재학습시키면 훈련한 단어에서만 향상이 일어났다. 이후 Kiran과 Thompson (2003)은 이 모의실험 결과를 유창성 실어증 환자군의 이름대기 중재에 적용하여 비전형적인 단어를 중재하는 것이 일반화 효과가 크다는 것을 증명하였다.
국내에서는 So, Hooshyar, Park과 Lim (2017)이 기계학습을 통해 치매를 조기판별할 수 있는 신경심리검사를 찾아내고자 한 바 있으나 기계학습 결과를 행동데이터로 검증한 연구는 찾아보기 힘들다. 본 연구에서는 기계학습으로 의미거리를 측정하고 그것을 행동데이터로 직접 증명하는 새로운 시도를 하였다. 특히 본 연구에서 시도한 기계학습 기반 의미거리는 ‘동사-명사’ 개별 자극에 대한 의미거리를 하나씩 정량화하여 나타낼 수 있다는 강점이 있어 중재 자극 선정 과정에서 임상적으로 유용하게 활용될 수 있다. 예를 들어, 신경언어장애군의 동사 중재 이론 중 복잡성 이론(Complexity Account of Treatment Efficacy)에 따르면 복잡한 구조로부터 중재를 시작할 경우 단순한 구조 산출로까지 일반화가 일어나지만, 단순한 구조로부터 중재를 시작하면 복잡한 구조의 산출로까지 일반화가 일어나지 않는다고 하였다(Thompson, Shapiro, Kiran, & Sobecks, 2003). 복잡성 이론에 기초한 중재 연구들은 중재 자극의 난이도를 조절하는 방법으로 내포문의 활용, 논항수의 증가, 명사의 전형성 및 친숙도 조절 등을 활용하여 중재 효과를 증명하였다(Kiran & Thompson, 2003; Schneider & Thompson, 2003; Thompson et al., 2003; Thompson & Shapiro, 2005;). 본 연구에서 제시한 의미거리도 중재 난이도 조절하는 데 있어 또 하나의 기준으로 활용할 수 있다. 예를 들어, 의미거리가 먼 명사부터 중재하는 것이 한국어에서도 일반화 효과를 극대화하는 방법이 될 수 있는지에 대한 검증에 본 자료를 활용할 수 있을 것이다. 이에 본 연구는 목표 동사와 주격 및 목적격 명사의 빈도수 및 기계학습 기반 의미거리를 클라우드 기반으로 공개하여 언어치료사들이 적극적으로 활용할 수 있게 하였다. 특히 생략이 잦아 중재 자극으로써의 효율성이 낮을 가능성이 큰 주격 명사보다는 목적격 명사 위주의 활용이 적절할 것으로 사료된다. 다만 본 연구는 기계학습으로 산출한 의미거리와 행동데이터 간 상관관계를 알아본 첫 시도였기 때문에 목표 동사와 최대·최소 거리에 위치한 명사만을 검증하였다는 실험적 한계를 가진다. 따라서 기계학습과 행동데이터 간 검증방법을 보다 다양화하는 후속연구가 필요할 것으로 보인다. 예를 들어 명사를 기계학습에 기반한 의미거리에 따라 범주화하고, 각 범주에서 모두 한국어 화자의 의미거리 평정과 정적 상관관계를 나타내는지 검증하는 방법도 대안으로 생각해 볼 수 있다.
본 연구에서 빅데이터를 기반으로 제시한 한국어 동사의 주격 명사 및 목적격 명사의 특징은 임상적 가설을 뒷받침하는 기초자료로써 유용하게 사용될 수 있다. 특히 본 연구는 누구나 활용할 수 있도록 클라우드 기반으로 원자료를 공개하여 한국어를 사용하는 신경언어장애군에게 적합한 동사 중재 자극을 선정하는 데 기여를 하고자 하였다. 차후에는 정제된 교과서 말뭉치와 성격을 달리하는 구어 말뭉치와의 비교를 통해 한국어 특징을 밝혀 최적의 동사 중재 자극을 선정하기 위한 연구가 지속될 필요가 있다. 아울러 선정한 중재 자극을 치료에 적용하여 효과성에 대한 부분도 검증되어야 할 것이다.