


읽기의 궁극적인 목표인 읽기이해에 도달하기 위해서는 정확하고 빠르게 읽는 단계를 거쳐야만 한다. 읽기에서 정확도가 부족하면 읽기속도가 증가하는데 방해가 될 것이며 정확도가 높더라도 읽는 속도가 느리다면 독자는 글자 하나하나를 해독하는 데 너무 많은 에너지를 사용해야 하기 때문에 글에 담긴 내용을 충분히 파악하고 이해하는 데 어려움을 갖게 될 것이다. 읽기발달의 단계를 정확성과 속도의 관점에서 본 LaBerge와 Samuels (1974)는 읽기발달을 3단계로 설명하면서 첫 번째 단계는 각 단어의 낱글자에 해당하는 음소를 찾아 연결하는 것의 미숙함으로 인해 정확도와 읽기 속도가 낮은 단계라고 보았다. 두 번째 단계에서는 점차 익숙한 단어들이 늘어나면서 비록 읽기 속도는 여전히 느리지만 읽기 정확도가 증가한다고 했다. 마지막 단계에서는 단어 재인이 자동화되면서 읽기 속도가 증가한다고 보았다.
읽기발달에 대해 정확도와 속도의 두 가지 요인으로 분리시켜 연구한 실험연구들을 살펴보면 Juul, Poulsen과 Elbro (2014)는 덴마크어를 사용하는 172명의 일반아동을 대상으로 실시한 종단연구에서 단어읽기의 정확도가 70% 이상 도달했을 때 단어읽기 속도의 발달이 가속화된다고 보고함으로써 읽기 정확도가 선행적으로 확보된 이후에서야 읽기 속도의 발달이 증가하며 이를 통해 읽기 정확도는 비교적 이른 연령대에 천장에 도달하지만 속도의 발달은 이후에도 계속 진행될 수 있을 것임을 주장하였다.
그동안 수많은 연구에서 읽기능력에 대한 예측요인으로 음운인식 능력과 빠른 이름대기 능력을 설명해왔다(Arnell, Joanisse, Klein, Busseri, & Tannock, 2009; Cho, 2011; de Jong & van der Leij, 2003; Furns & Samuelsson, 2011; Georgiou, Parrila, Kirby, & Stephenson, 2008; Kim, Yoo, & Kim, 2010; Kirby, Parrila, & Pfeiffer, 2003; Song & Hwang, 2005). 음운인식능력은 대체로 초등학교 입학 전후 정규 읽기 교육이 시작되는 무렵부터는 읽기 유창성에 대한 예측력이 낮아졌으나 반면 빠른이름대기는 초등 저학년까지는 읽기 유창성에 대한 설명력이 음운인식과 비슷하거나 더 낮지만 학년이 높아질수록 상관이 강해졌으며 초등학교 고학년까지의 읽기능력 예측요인으로 작용한다고 보고되었다(Landerl & Wimmer, 2008). 또한 빠른이름대기는 독일어나 한국어와 같은 표층체계의 언어권에서는 읽기발달의 초기단계에서부터 음운인식보다 더 안정적인 예측요인인 것으로 보고되었다(Ziegler et al., 2010).
이와 비슷한 맥락으로 여러 연구들에서 음소인식능력을 단어읽기의 정확도를 예측하는 요인으로, 빠른이름대기를 단어읽기의 속도를 예측하는 요인으로 밝히며 읽기발달에서 정확도의 확보보다는 속도의 증가가 관건이 되는 표층언어체계에서 빠른이름대기 능력이 중요하다고 설명했다(Juul et al., 2014; Landerl & Wimmer, 2008; Torgesen, Wagner, Rashotte, Burgess, & Hecht, 1997).
de Jong과 Leij (2003)에 따르면 난독학생은 일반학생과 비슷하게 초등학교에 입학해서 정규 읽기학습이 시작된 이후부터는 음운인식의 문제 중 음절수준의 어려움은 차차 극복되는 양상을 보이지만, 빠른이름대기에서의 부진은 초등학교 입학 전부터 입학 후 6학년 말까지도 꾸준히 지속되었다고 보고하였다.
특히 Schatschneider, Fletcher, Francis, Carlson과 Foorman (2004)의 연구에서는 빠른이름대기의 읽기 속도와의 관련성을 강조하며 낱글자 빠른이름대기 과제에 대해서 읽기 유창성 측정의 간략한 양식으로 활용할 수 있음을 주장하였다.
빠른이름대기는 친숙한 사물, 글자, 숫자, 색깔 등으로 이루어진 일련의 자극에 대해 최대한 빠르게 이름을 말하도록 요구되는 과제이다. 빠른이름대기는 이름대기와 읽기의 관계에 대한 음운적, 언어적, 시각적 처리를 포함하는 인지능력이자, 읽기능력 특히 읽기 유창성을 예측하는 독립적인 요인으로 설명하기도 하고(Norton & Wolf, 2012), 음운인식, 음운기억, 빠른이름대기로 이루어진 전체 음운처리과정의 하위 구성요소라고 설명하기도 한다(Wagner & Torgesen, 1987). 빠른이름대기 능력과 읽기는 둘 다 시각적인 자극에 주의를 기울여서 그 패턴을 분석하여 그것이 주는 시각적 정보를 장기기억에 저장된 철자배열의 정보, 음운적 정보, 의미적 정보 등과 통합하고 음운적 부호로 회상하여 구어로 표현하는 과정이 필요하다. 바로 이러한 점에서 빠른이름대기 능력이 읽기 능력을 예측하는 중요한 요인이라고 보는 견해가 주장되고 있다(Araújo, Reis, Petersson, & Faísca, 2015; Norton & Wolf, 2012).
1976년 Denkla와 Rudel에 의해 색깔, 사물, 글자, 숫자와 같은 친숙한 아이템의 이름을 말하는 속도를 측정하는 과제로 개발된 이래로 40여 년 동안 빠른이름대기 과제의 다양한 형태가 제안되어왔다. 그러나 책을 읽는 방향인 왼쪽에서 오른쪽으로 연속된 항목을 말하고, 충분히 친숙한 아이템들을 사용한다는 기본적인 개념을 갖춘다면 빠른 이름대기 과제로써 적절하다고 여겨져 왔다(Norton & Wolf, 2012).
Roelofs (2006)는 시각적인 부호는 다르나 음운적인 부호를 일치시킨 주사위 눈, 숫자, 수 낱말의 빠른 이름대기 과제를 통해 이들의 기본구조 및 그림과 낱말이름대기의 관계를 연구하였다. ‘둘, 셋’이라는 수를 나타내는 글자 어휘와는 달리 숫자 ‘2, 3’은 어떻게 발음해야 하는지에 대한 단서가 전혀 없다는 점에서 숫자는 그림(pictures and dice)과 유사한 면이 있다. 그러나 결정적으로 글자와 숫자는 둘 다 조합이 가능한 상징체계의 기본 요소이고, 어휘를 구성할 수 있다는 점에서 숫자이름대기는 낱말이름대기와 같은 기전이라고 보았다 (Roelofs, 2006).
자폐스펙트럼장애 집단의 읽기 자동화 메커니즘의 특성을 빠른 이름대기 과제를 통해 알아보고자 한 Hogan-Brown, Hoedemaker, Gordon과 Losh (2014)의 연구에서는 빠른 이름대기 과제를 문자과제(낱글자, 숫자)와 비문자과제(색깔, 사물)로 나누어 문자과제를 더 자동화된 과제로, 비문자과제를 덜 자동화된 과제로 설명하였다. 또한 낱글자, 숫자와 같은 문자 빠른 이름대기 과제는 언어적인 처리(음운처리, 시각적-음운적 연결 처리)와 더 관련된 과제이고, 색깔, 사물과 같은 비문자 빠른 이름대기 과제는 집행기능과 연관되어 있다고 하여 빠른 이름대기 과제를 문자-비문자 과제로 나누어 설명하였다(Hogan-Brown et al., 2014).
영어권의 빠른 이름대기와 읽기 능력에 관한 메타분석결과 빠른 이름대기와 읽기 유창성의 상관이 높았고, 특히 문자 과제가 비문자 과제보다 읽기 능력과의 상관이 높았다. 또한 학년이 올라가더라도 빠른 이름대기는 읽기를 민감하게 예측하였다(Araújo et al., 2015).
국내 선행연구에서는 초등 저학년 음운해독부진 아동을 대상으로 한 연구에서 글자와 숫자 중 글자 빠른 이름대기만 단어읽기를 예측했고(Kim & Pae, 2012), 초등 3, 4학년 읽기부진 아동의 숫자와 사물 과제 중 사물 빠른 이름대기만 단어와 비단어 읽기를 예측했다(Park, Cho, & Yu, 2013). 초등 1학년 읽기 저성취 집단은 숫자에서 가장 빠른 반응속도를 보였으며 사물에서 가장 느린 반응속도를 보였고, 색깔과 숫자 정반응과 사물반응속도가 읽기 저성취의 조기선별에 중요했다고 보았다. 또한 정확도보다는 반응속도에서 집단간 차이가 크게 나타났다는 선행연구가 있다(Park & Kim, 2014; Park, 2015).
숫자 빠른 이름대기는 여러 연구에서 자주 사용되어온 과제이다. 그런데 한국어는 특유의 숫자 어휘에서의 이중 체계에 따른 난이도의 문제가 존재한다. 한국어의 기수사 체계는 한자어계 기수사(일, 이, 삼)와 고유어계 기수사(하나, 둘, 셋)의 두 가지가 있다.
한자어계 기수사와 고유어계 기수사의 난이도 차이가 발생하는 이유는 영유아기때 흔히 접하는 환경이 고유어이기 때문에 5세 이전에는 더 많이 사용되고 더 빨리 발달하지만 고유어계 기수사가 조합의 불규칙성으로 인해 습득이 어렵고 음절수가 길다는 단점과는 달리 한자어계 기수사는 생성과 조합의 규칙성으로 인해 습득이 쉽고, 음절수가 대부분 단일 음절이므로 발음과 기억에 용이하다는 특징이 있다는 점으로 설명된다(Hong, 1990).
또한 고유어계 기수사의 사용이 어려운 이유는 표상의 과정을 한번 더 거쳐야 하기 때문인데, 사용이 쉽고 사용빈도 역시 더 높은 한자어계 기수사에 비해 고유어계 기수사로 읽거나 말하거나 학습상황에서 문제풀이를 할 때 한자어계 기수사로 한번 더 표상을 한 다음 고유어계 기수사로 다시 표상을 하는 등의 문제가 발생한다는 점이다. 이러한 특징으로 인하여 한국아동은 초등학교 5학년까지 두 가지 체계의 기수사 사용에서 어려움을 보이며, 개념적 표상체계의 발달이 이루어지는 만 12세 이후 초등 6학년 후 비약적으로 발달한다고 하였다(Hong, 1990; Song, 1990).
본 연구에서는 한국어를 사용하는 학령기 난독아동과 일반아동의 다양한 빠른 이름대기 과제수행의 양상을 알아보고 비교하고자 한다. 이를 위해 살펴볼 연구문제는 다음과 같다.
첫째, 난독아동과 일반아동은 빠른 이름대기 과제의 유형(문자 및 비문자)에 따라 유의한 차이가 있는가?
둘째, 난독아동과 일반아동은 난이도(한자어계 및 고유어계 기수사)에 따른 숫자 빠른 이름대기 수행력에서 유의한 차이가 있는가?
셋째, 난독아동과 일반아동을 가장 잘 판별해주는 빠른 이름대기 과제의 조건은 무엇인가?
연구방법
연구대상
본 연구에 참여한 난독아동은 서울 및 수도권에 거주하는 (1) 초등학교 1학년에서 5학년 사이에 해당하고, (2) 교사나 부모에 의해 읽기 어려움이 보고되었다. 또한 (3) 소아정신과 전문의에게 난독증으로 진단받았으며, (4) 표준화된 지능검사 결과 전체 지능지수가 −1 표준편차(IQ 85) 이상, (5) 수용·표현어휘력검사(REVT; Kim, Hong, Kim, Jang, & Lee, 2009)에서 수용어휘 점수가 −1.25 표준편차 이상, (6) 표준화된 읽기검사(한국어 읽기검사, KOLRA; Pae, Kim, Yoon, & Jang, 2015)의 해독검사에서 −2 SD 미만인 아동이며, (7) 정서 및 감각 기능의 문제가 없는 아동만을 대상으로 하였다. 이들의 인지능력은 지능검사(K-ABC-II; Moon, 2014)에서 평균 103.67이며, 생활연령 평균 104.83개월에 속하는 아동으로 1학년 1명, 2학년 2명, 3학년 6명, 4학년 1명, 5학년 2명, 총 12명의 아동이 선정되었다.
일반아동은 서울 및 수도권에 거주하는 (1) 담임교사 혹은 학부모에 의해 작성된 한국어 읽기검사(KOLRA)의 읽기설문지 결과 총점 10점 중 0점을 얻음으로써 읽기 어려움이 없는 것으로 보고된 아동으로, (2) 검사 당시 한글 난독아동과 학년 수준이 일치하고, (3) REVT 수용어휘 점수가 −1.25 표준편차 이상, (4) 학습, 정서 및 감각 기능의 문제가 보고되지 않은 아동만을 대상으로 하였다. 선정된 아동은 총 12명이었으며, 2학년 3명, 3학년 6명, 4학년 1명, 5학년 2명이었다. 이들의 생활연령 평균은 104.67개월이었다. 두 집단의 통제가 잘 이루어졌는지 확인하기 위해 일원분산분석(one-way ANOVA)을 실시한 결과, 생활연령에 통계적으로 유의한 차이가 없었다 (p>.05). 그러나 수용어휘력에서는 두 집단 간 차이가 통계적으로 유의하게 나타났다 (p < .05). 난독아동과 일반아동에 대한 생활연령, 수용 어휘력 점수의 평균과 표준편차 및 난독아동의 비언어성지능, 해독검사의 평균과 표준편차는 Table 1에 제시하였다.
Table 1.
Participants' characteristics
| Dyslexic (N = 12) | Normal (N = 12) | F | |
|---|---|---|---|
| Age (mo) | 104.83 (11.61) | 104.67 (12.48) | .001 |
| REVT_R (mo) | 105.25 (26.92) | 127.00 (10.90) | 6.73** |
| Nonverval IQ | 103.67 (16.66) | ||
| KOLRA_decoding (%ile) | 8.58 (8.32) |
REVT_R = Receptive test of Receptive & Expressive Vocabulary Test (Kim, Hong, Kim, Jang & Lee, 2010); Nonverbal IQ=Korean Kaufman Assessment Battery for Children II (Moon, 2014); KOLRA_decoding=word decoding test of Korean Language-based Reading Assessment (Pae, Kim, Yoon, & Jang, 2015).
연구도구
본 연구에서 사용한 빠른 이름대기 과제는 Denkla와 Rudel (1976)의 선행연구에서 제시된 검사의 구성 요소를 참고하여 9열 4행으로 이루어진 숫자(아라비아 숫자로 2세트), 색깔, 사물, 낱글자, 음절글자의 총 6가지의 빠른 이름대기 과제를 제작하였다. 검사문항의 구성은 발달순서상 일찍 발달이 시작되는 고빈도의 어휘를 기본 원칙으로, 수용 ·표현어휘력 검사(REVT; Kim et al., 2009), 한국 아동의 표현어휘 연구(배소영 외, 2001)를 참고하여 선택하였다. 일반 초등학교 1–6학년에 속하는 총 20명을 대상으로 한 예비연구를 통해 아동이 쉽게 검사에 참여하고 집중을 유지할 수 있는지를 고려하여 문항수와 제시형태를 선정하였다. 모든 빠른 이름대기 과제에는 동일한 원칙으로 제작된 6열 2행의 연습문항이 포함되었다.
유형에 따른 과제 분류
난이도에 따른 과제 분류 (한자어계 기수사 및 고유어계 기수사)
난이도에 따른 과제 분류는 다음과 같다. 아라비아 숫자 중 1부터 8까지 중에서 무선적으로 배치하였고 한자어계 기수사(예: 일, 이, 삼)와 고유어계 기수사(예: 하나, 둘, 셋)로 반응할 수 있도록 검사문항을 두 세트로 제작하였다.
검사문항의 실시
검사문항은 조용한 공간에서 검사자와 대상아동 일대일의 조건으로 노트북 컴퓨터를 이용하여 그림자극과 소리자극(과제의 시작을 알리는 ‘딩동’ 소리와 문항 설명 스크립트)을 파워포인트로 제시하였다. 본 문항을 제시하기 전 연습문항을 먼저 제시하여 참여자가 실제로 이름대기과제를 수행해보고, 검사자의 의도를 충분히 이해할 수 있도록 설명을 제공하였다. 본 문항의 설명 스크립트는 다음과 같다. “화면이 바뀌고 ‘딩동’ 소리가 나면 방금 보았던 숫자들의 이름을 하나도 빠짐없이 할 수 있는 한 가장 빠르게 말해주세요. 책을 읽는 것처럼 왼쪽에서 오른쪽 방향으로 말하면 돼요. 이름을 다 말했으면 한 줄 내려가서 다시 왼쪽부터 말해주세요.” 설명 스크립트를 마치면 ‘딩동’ 소리와 함께 그림자극이 나타나고 참여자가 빠른 이름대기 과제를 실시하며 이때 준비한 초시계와 검사지로 반응시간과 맞은 문항을 기록하였다. 아동이 오반응 후 자가 수정하여 다시 정반응을 했을 경우 이는 정반응으로 처리 하였다.
자료분석 및 결과처리
6가지 과제 각각에 대해 정반응율과 반응시간을 측정하였다. 반응시간은 디지털 초시계를 이용하여 ‘초’단위로 측정하였고 정반응율은 정반응한 문항수를 전체 문항으로 나누고 100을 곱하여 백분율로 표시하였다.
통계적 분석은 SPSS ver. 21을 사용하였다. 두 집단 간 과제 유형(문자: 낱글자, 음절글자) 및 비문자: 색깔, 사물)와 난이도(한자어계 기수사 및 고유어계 기수사)에 따른 정확도와 반응시간의 수행차이를 비교하기 위하여 집단과 과제유형을 독립변인으로 한 이원혼합 분산분석(2-way mixed ANOVA)을 실시하였으며, 한자어계 기수사와 고유어계 기수사의 정확도와 반응시간 중 두 집단을 가장 잘 판별해주는 요인이 무엇인지 알아보기 위해 단계적 판별분석(stepwise discriminant analyses)을 실시하였다.
연구결과
과제 유형(문자-비문자)에 따른 난독아동과 일반아동의 빠른 이름대기 수행
문자와 비문자 빠른 이름대기 과제별 수행차이가 나타나는지 알아보기 위해 음절글자, 낱글자, 색깔, 사물 빠른 이름대기 정확도 수행을 이원혼합배치 분산분석을 통해 비교한 결과, 집단 간 차이가 유의하지 않았고(F(1,22) = 2.088, p =.163), 과제 간 차이 또한 유의하지 않은 것으로 나타났다(F(1,22) =1.385, p = .252). 집단과 과제 유형에 따른 상호작용 효과가 유의미하지 않은 것으로 나타났다(F(1,22) = 1.845, p =.183). 즉 난독아동과 일반아동의 문자-비문자 빠른 이름대기 과제별 정확도에서는 두 집단 간 통계적으로 유의미한 차이가 나타나지 않았다. 이에 대한 결과는 Figure 1과 Table 2에 제시하였다.
Figure 1.
Accuracy of rapid automatized naming (RAN) according to alphanu-50 meric/non-alphanumeric tasks.
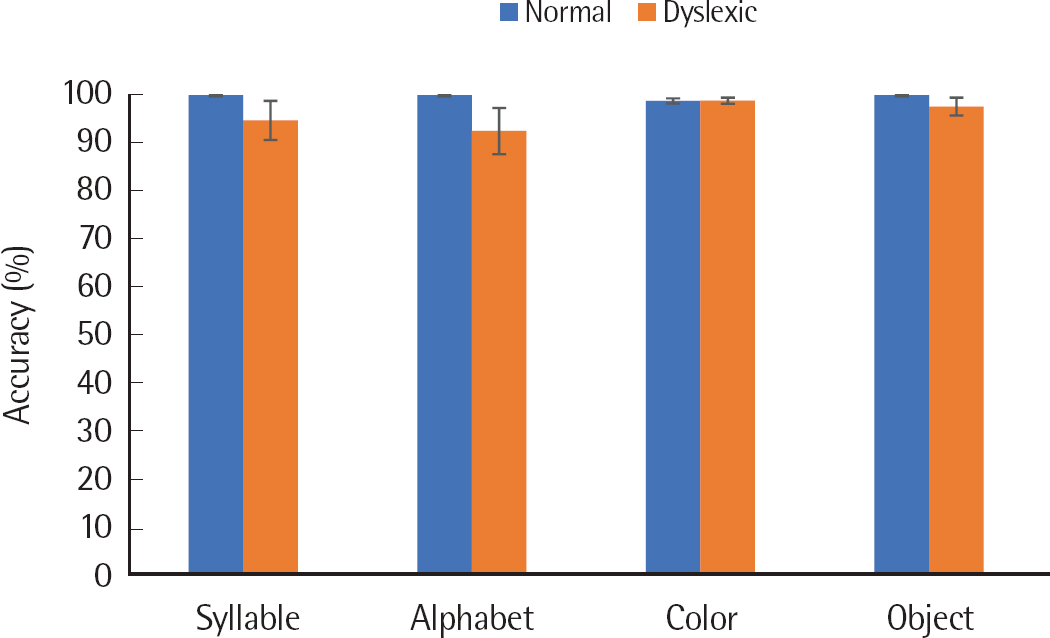
Table 2.
Accuracy (%) of RAN according to task type
| Normal (N = 12) | Dyslexic (N = 12) | |
|---|---|---|
| Syllable | 99.77 (.81) | 94.55 (14.1) |
| Alphabet | 99.77 (.81) | 92.35 (16.63) |
| Color | 98.60 (1.88) | 98.60 (2.23) |
| Object | 99.77 (.81) | 97.45 (6.43) |
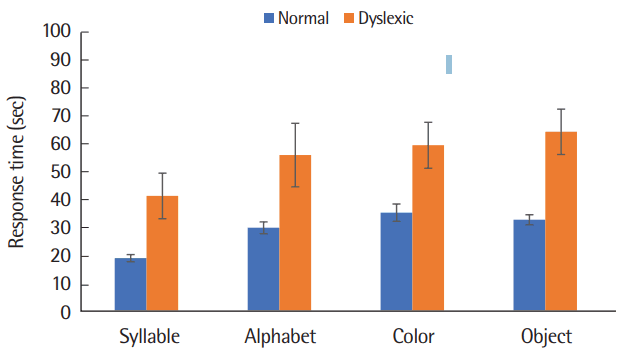
문자와 비문자 빠른 이름대기 과제별 반응시간의 수행 차이가 있는지 알아보기 위해 이원혼합배치 분산분석을 실시한 결과, 집단 간 차이는 통계적으로 유의하였다(F(1,22) = 9.382, p < .05). 즉 난독아동은 일반아동에 비해 유의하게 긴 반응시간을 보였다. 과제간 차이 또한 통계적으로 유의하였다(F(1,22) =13.853, p < .001). 어느 과제 간 반응시간의 차이가 나타났는지 알아보기 위해 Bonferroni 다중비교를 실시한 결과 음절글자와 낱글자(p < .05), 음절글자와 색깔(p < .001), 음절글자와 사물(p < .001)의 반응시간에서 차이가 나타났다. 즉, 문자-비문자 빠른 이름대기 과제 중에서는 음절글자(M= 30.293, SE = 4.122)의 반응시간이 낱글자(M= 43.034, SE = 5.284), 색깔(M= 47.485, SE= 4.400), 사물(M= 48.624, SE= 4.154) 반응시간보다 유의미하게 더 짧은 것으로 나타났고, 반응시간은 음절글자 < 낱글자 <색깔 < 사물 순으로 더 길게 소요된 것으로 나타났다. 집단과 과제 반응시간의 상호작용 효과는 유의하지 않은 것으로 나타났다(F(1,22) = 0.775, p =.512). 이에 대한 결과는 Figure 2와 Table 3에 제시하였다.
Figure 2.
Response time of rapid automatized naming (RAN) according to alphanumeric/non-alphanumeric tasks.
난이도에 따른 난독아동과 일반아동의 빠른 이름대기 과제별 수행
과제의 난이도에 따른 수행차이가 나타나는지 알아보기 위해 한자어계 기수사와 고유어계 기수사의 숫자 빠른 이름대기 정확도 수행을 이원혼합배치 분산분석을 통해 비교한 결과, 집단 간 차이가 유의하였다 (F(1,22) = 5.988, p < .05). 즉, 난독아동은 일반아동에 비해 과제의 난이도가 높았을 때 유의미하게 더 낮은 정확도를 보였다. 과제 유형에 관한 주효과는 통계적으로 유의한 것으로 나타났다 (F(1,22) =10.067, p < .05). 난이도가 높은 고유어계 기수사의 정확도가 한자어계 기수사의 정확도에 비해 유의하게 낮은 것으로 나타났다. 또한 집단과 과제 정확도의 상호작용 효과가 유의미한 것으로 나타났다 (F(1,22) = 5.420, p < .05). 난독아동의 고유어계 기수사와 한자어계 기수사의 정확도 수행 차이가 일반아동의 고유어계 기수사와 한자어계 기수사의 정확도 수행 차이보다 유의하게 큼으로써 과제의 난이도가 높을 때 난독아동의 정확도 수행이 더욱 저조한 것으로 나타났다. 이에 대한 결과는 Figure 3과 Table 4에 제시하였다.
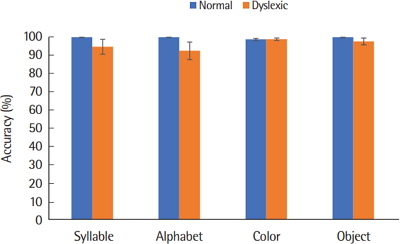
Table 4.
Accuracy (%) of RAN according to task difficulty
| Normal (N=12) | Dyslexic (N = 12) | |
|---|---|---|
| Sino-Korean cardinal numerals | 100 (0) | 99.77 (0.81) |
| Native-Korean cardinal numerals | 97.68 (7.19) | 84.70 (17.41) |
일반아동과 난독아동의 한자어계 기수사와 고유어계 기수사의 반응시간을 비교하기 위하여 이원혼합배치 분산분석을 실시한 결과, 일반아동과 난독아동의 집단 간 주효과가 통계적으로 유의미하게 나타났다 (F(1,22) = 62.231, p < .0001). 즉, 난독아동은 일반아동에 비해 유의하게 더 긴 반응시간이 걸린 것으로 나타났다. 한자어계 기수사와 고유어계 기수사의 과제 간 주효과 역시 통계적으로 유의미한 것으로 나타났다 (F(1,22) =12.557, p < .005). 즉, 한자어계 기수사보다 고유어계 기수사의 반응시간이 더 긴 것으로 나타났다. 집단과 과제 간의 상호작용효과는 통계적으로 유의미하지 않은 것으로 나타났다 (F(1,22) = 2.412, p =.135). 이에 대한 결과는 Figure 4와 Table 5에 제시하였다.
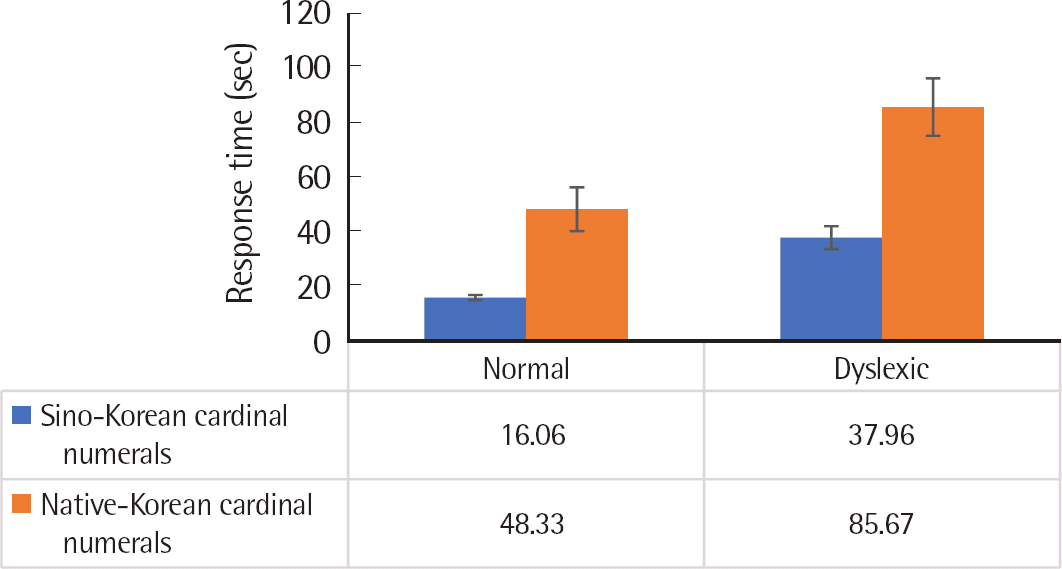
난독아동과 일반아동 대상 판별분석
난독아동과 일반아동의 집단특성을 가장 잘 판별할 수 있는 요소는 무엇인지 파악하고자 정확도와 반응시간에 대해 각각 단계선택 판별분석(stepwise estimation-discriminate analysis)을 실시하였다. 투입된 독립변수는 숫자(한자어계 기수사, 고유어계 기수사), 음절글자, 낱글자, 색깔, 사물과제에 대해 정확도 및 반응속도로 나누어 각각 입력하였다. 정확도 과제에서는 도출된 판별함수로부터 입력된 6가지의 독립변수 중에서 모델1의 고유어계 기수사의 정확도, 낱글자 정확도의 결합이 집단을 가장 정확히 예측할 수 있는 유의미한 요인인 것으로 나타났다. 이때 전체 식의 Wilks의 람다 값과 정준판별분석을 통해 도출된 판별함수에 의하면 모델1에서 일반아동을 일반아동으로 판별하는 특이도(specificity)는 91.7%, 난독아동을 난독아동으로 판별하는 민감도(sensitivity)는 58.3%로 원 집단 케이스 중 총 75%가 정확하게 분류될 수 있는 것으로 나타났다(χ2 = 9.499, Wilks' Lambda=.636, p < .05). 이에 대한 세부적인 결과는 Table 6과 같다.
Table 6.
Classification table from stepwise discriminant analysis of accuracy task
| Independent variable | Eigenvalue (Rc) | χ2 | Wilks' Lambda | Specificity (%) | Sensitivity (%) | Total (%) | |
|---|---|---|---|---|---|---|---|
| Model 1 | N_NK_ACC | .572 (.603) | 9.499 | .636 (p <.05) | 91.7 | 58.3 | 75 |
| ALPHA_ACC |
반응시간별로 살펴본 결과, 도출된 판별함수로부터 입력된 6가지의 독립변수 중에서 모델1의 사물 반응시간이 집단을 가장 정확히 예측할 수 있는 유의미한 요인인 것으로 나타났다. 이때 전체 식의 Wilks의 람다 값과 정준판별분석을 통해 도출된 판별함수에 의하면 모델1에서 일반아동을 일반아동으로 판별하는 특이도(specificity)는 100%, 난독아동을 난독아동으로 판별하는 민감도(sensitivity)는 58.3%로 원 집단 케이스 중 총 79.2%가 정확하게 분류될 수 있는 것으로 나타났다(χ2 =10.786, Wilks' Lambda=.606, p<.05). 이에 대한 세부적인 결과는 Table 7과 같다.
논의 및 결론
본 연구에서는 난독아동과 일반아동의 빠른 이름대기 과제에 대한 수행의 양상을 알아보기 위하여 총 6가지의 빠른 이름대기 과제를 수행하고 두 집단 간 정확도와 반응시간을 분석하였다. 또한 빠른 이름대기 과제 중 난독아동과 일반아동을 판별하는 요인이 무엇인지 알아보기 위하여 단계적 판별분석을 실시하였다. 이에 대한 결론은 다음과 같다.
첫째, 난독아동은 문자-비문자 빠른 이름대기 과제의 수행에서 정확도에서는 일반아동과 유의미한 수행 차이를 보이지 않았다. 과제 간의 정확도에서도 차이가 나타나지 않았다. 즉 문자-비문자 빠른 이름대기 과제에서는 두 집단 간 차이도, 과제 간의 차이도 나타나지 않았다. 반응시간에서는 집단 간 수행차이가 나타났고 과제 간에도 차이가 나타났으나, 음절글자와 나머지 3가지(낱글자, 색깔, 사물)의 과제 간에서만 차이가 나타났다. 난독아동과 일반아동의 문자-비문자 빠른 이름대기 양상에서는 차이점이 나타나지 않았으며 난독아동은 일반아동에 비해 빠른 이름대기 과제 전체에서 저조한 수행을 보이는 것으로 확인되었다. 이는 숫자, 글자, 사물, 색깔 과제에 대해 읽기 저성취 집단의 정반응률 수행이 일반집단에 비해 저조하였고 두 집단 모두에서 숫자와 글자 과제에서 보다는 사물과 색깔 과제에서의 반응속도가 지연되었다는 선행연구와 부분적으로 유사한 결과이다(Park & Kim, 2014). 본 연구에서 정확도에서는 4가지 과제 모두에서 두 집단 간 차이가 나타나지 않았는데, 이는 대상자들의 학년 및 대상자들이 지닌 읽기문제의 특성과 관련된 것으로 보인다. 1학년 읽기 저성취 학생을 대상으로 한 Park과 Kim (2014)의 연구에서는 읽기 저성취 집단의 정확도와 반응속도 둘 다 통제집단에 비해 부진했으나 본 연구의 대상자는 고학년이 다수 포함되었기 때문에 정확도에서는 집단 간 차이가 나타나지 않았을 가능성이 있다. 그럼에도 불구하고 난독집단에서 나타난 지연된 반응시간은 빠른 이름대기 과제 수행에서 두 집단의 차이는 반응시간임을 보여주는 것이라고 볼 수 있다. 반응시간에 대한 과제 간 차이가 유의미하게 나타났는데 이 역시 대상자의 연령과 관련하여 생각해 볼 수 있을 것으로 보인다. 받침 없는 1음절 수준의 자극은 한글 조기교육이 광범위하게 이루어지는 현 상황에서 대상자들에게 이미 충분히 자동화가 이루어졌을 가능성이 있을 것으로 보이며, 이에 따라 결과 해석에 유의해야 할 것으로 보인다.
둘째, 과제 난이도에 따른 난독아동의 빠른 이름대기 과제 수행은 다음과 같다. 난독아동은 한자어계 기수사의 정확도에서는 일반아동과 수행차이가 유의미하게 나타나지 않았지만 고유어계 기수사의 정확도에서는 유의미한 차이가 나타났다. 즉 난독아동은 난이도가 낮은 과제에서는 일반아동과 차이가 없었으나 과제의 난이도가 높아지자 일반아동보다 유의미하게 저조한 빠른 이름대기 수행을 나타냈다. 난독아동은 과제의 자극이 이미 친숙한 어휘임에도 불구하고(숫자) 심성 어휘집에 이중으로 입력된 숫자읽기에 대한 정보를 인출하는 데 어려움을 보였으며, 일반아동도 어려움을 보였으나 일반아동이 보이는 어려움보다 더 많은 어려움(정확도가 낮아지고 반응시간은 길어지는)을 보였다.
이와 관련하여 과제의 조건에 따른 난독인의 음운처리 수행을 보고한 연구가 있다. Ramus와 Szenkovits (2008)는 난독집단은 음운적 표상에서 일반인과 차이를 보이지 않을 수 있으나, 단기기억, 시간 제한, 경쟁적인 과제 등 압박감이 있는 상황에서 음운적 표상에 접근하는 데에 어려움을 보일 수 있다고 보았다. 고유어계 기수사는 한자어계 기수사에 비해 조합의 불규칙성 때문에 습득이 더 어렵고, 음절수가 더 길기 때문에 기억(음운적 부호의 회상)하거나 발음(구어로 표현)하는 데 더 어렵다. 또한 고유어계 기수사는 읽거나 말할 때 주로 한자어계 기수사로 한번 더 표상의 과정을 거치게 되는데, 이러한 점은 난독아동에게 인지적 부담을 부과하여 빠른 이름대기 과제를 수행하는 데 반응시간의 지연을 야기했을 가능성이 있다.
셋째, 본 연구에서는 일반아동과 해독에 어려움을 보이는 난독아동을 판별하는데 정확도에서는 고유어계 기수사 정확도와 낱글자 정확도가 기여를 했고, 반응시간에서는 사물 반응시간이 기여를 하였다. 판별분석의 결과와 위의 결과들을 종합하여 판단했을 때 빠른 이름대기에 대한 일반집단과 난독집단의 차이를 전반적으로 이끌어가는 변수는 반응시간인 것으로 보인다. 난독집단은 음운인식, 음운단기기억, 어휘 회상을 포함한 음운적 처리에 어려움을 겪는데, 이것이 반응시간의 지연을 일으키며 반응시간이 지연될수록 음운적 기억과 회상에 또 다른 압박을 가져다 주어 결국 읽기과정 전반에도 악영향을 줄 것으로 보인다(Araújo et al., 2015; Norton & Wolf, 2012). 또한 난독인의 빠른 이름대기에서의 지연된 반응속도를 신경학적인 문제가 기저가 되는 시간 지연의 문제(timing deficit)라는 견해도 제안되고 있다(Hogan-Brown et al., 2014; Norton & Wolf, 2012).
만일 일반집단과 난독집단 간의 빠른 이름대기의 정확도 차이를 살펴보고자 할 때에는 난이도가 높은 과제를 활용하는 것이 효과적일 것으로 보인다. 여러가지 빠른 이름대기 과제 중 난독 집단의 특성을 더욱 잘 드러낼 수 있게 하는 정확도 측정 과제의 요소는 높은 난이도인 것으로 보인다.
본 연구의 제한점으로는 통제집단의 선정을 교사 및 보호자의 보고에 의존하여 지능과 읽기능력을 통제했다는 점이 있다. 후속 연구에서는 표준화된 지능검사 및 읽기검사를 사용하여 일반아동의 지능과 읽기능력을 통제하는 것이 필요할 것으로 보인다. 본 연구에서는 난독아동에 대해 어휘력만으로 언어능력을 선별하였으나 후속연구에서는 보다 종합적인 언어능력의 평가가 추가되는 것이 필요할 것으로 보인다. 또한 난독아동과 일반아동의 집단특성을 가장 잘 판별할 수 있는 요소는 무엇인지 파악하고자 판별분석을 실시하였으나 분석하고자 한 독립변수에 비해 대상자 수가 제한적이었다. 또한 일반집단을 일반집단으로 구분하는 민감도는 정확도와 반응시간 각각 91.7%, 100%로 높은 편이나, 난독집단을 난독집단으로 구분하는 특이도는 두가지 모두 58.3%로 변별력이 낮은 것으로 나타나 해석에 유의해야 할 것으로 보인다. 이에 충분한 대상자수를 확보한 후속연구가 필요할 것으로 보인다.
이 외에도 과제별 빠른 이름대기 능력과 난독아동의 읽기해독 능력의 관련성 및 양상에 대한 후속 연구가 이루어진다면 임상현장에 유익한 정보를 제공할 수 있을 것으로 보인다.


